# 安装包
if (!requireNamespace("ggplot2", quietly = TRUE)) {
install.packages("ggplot2")
}
# 加载包
library(ggplot2)饼图
饼图是统计学的基础图表,用大小不同的扇形区域来表示各项的大小。从饼图中可以直观得了解各项数据在总体数据的比重。
示例
图中是一个非常基础的饼图,不同颜色和大小的扇形区域代表不同项的数据,可以直观看出各组数据在整体数据中的比重。
环境配置
系统要求: 跨平台(Linux/MacOS/Windows)
编程语言:R
依赖包:
ggplot2
sessioninfo::session_info("attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.6.0 (2026-04-24)
os Ubuntu 24.04.4 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate C.UTF-8
ctype C.UTF-8
tz UTC
date 2026-05-09
pandoc 3.1.3 @ /usr/bin/ (via rmarkdown)
quarto 1.9.37 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
ggplot2 * 4.0.3.9000 2026-05-04 [1] Github (tidyverse/ggplot2@6870419)
[1] /home/runner/work/_temp/Library
[2] /opt/R/4.6.0/lib/R/site-library
[3] /opt/R/4.6.0/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────数据准备
数据来自PubMed的论文”The epidemiology of lung cancer in Hungary based on the characteristics of patients diagnosed in 2018”[1],其中的肺癌分期统计。
# 数据写入,一列分组,一列值
data <- data.frame(
group = c("I", "II", "III", "IV", "NA"),
value = c(402, 955, 1252, 3343, 3567)
)
head(data) group value
1 I 402
2 II 955
3 III 1252
4 IV 3343
5 NA 3567可视化
1. 基础饼图
# 基本绘图—条形图
p <- ggplot(data, aes(x = "", y = value, fill = group)) +
geom_col() # 先绘制条形图,再经过coord_polar()变换成饼图
p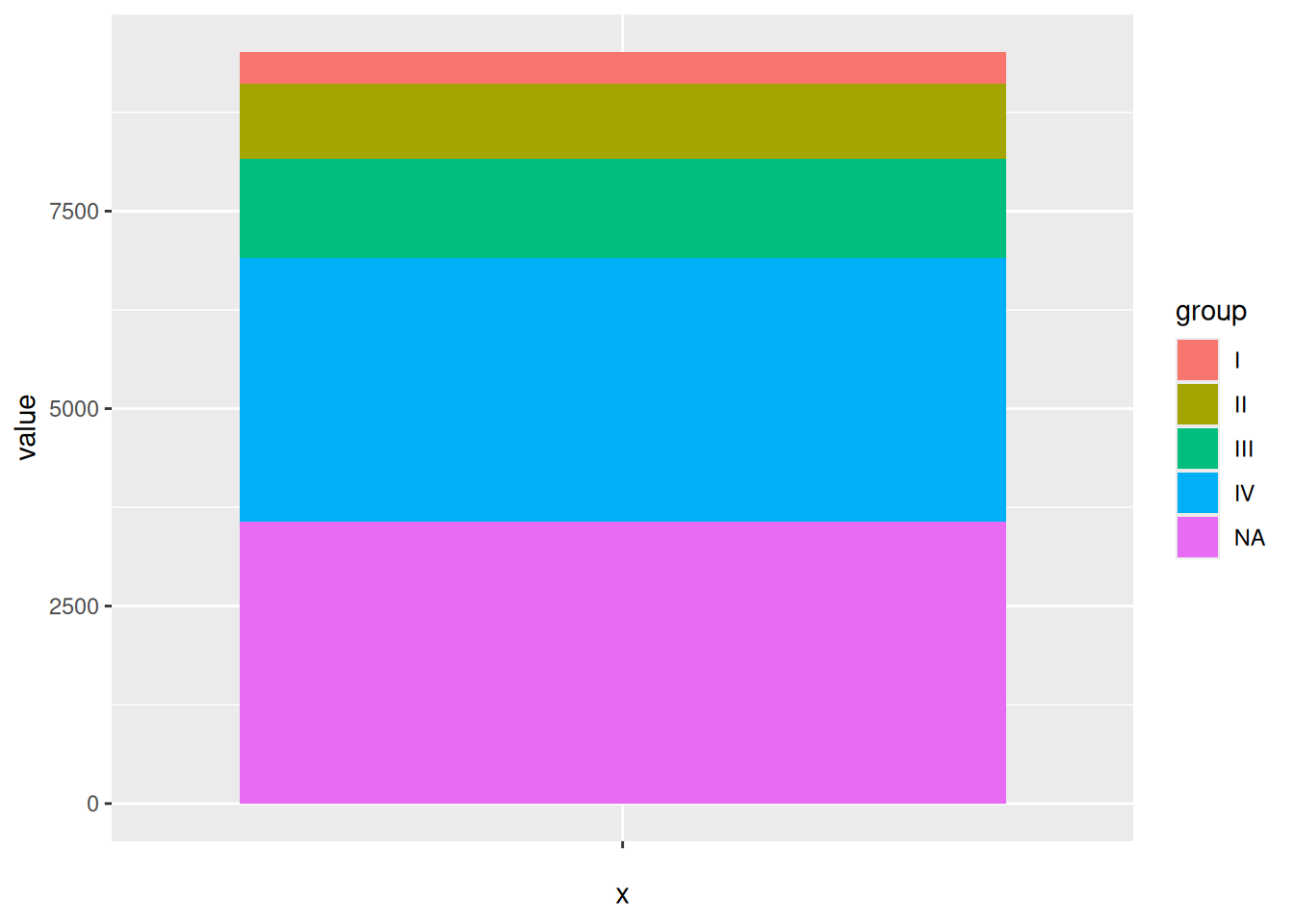
绘制条形图是ggplot2绘制饼图的中间步骤,再经过coord_polar()进行坐标极点化就能得到饼图。
# 基础饼图
p <- ggplot(data, aes(x = "", y = value, fill = group)) +
geom_col() + # 先绘制条形图,再经过coord_polar()变换成饼图
coord_polar(theta = "y") # 用于绘制饼图
p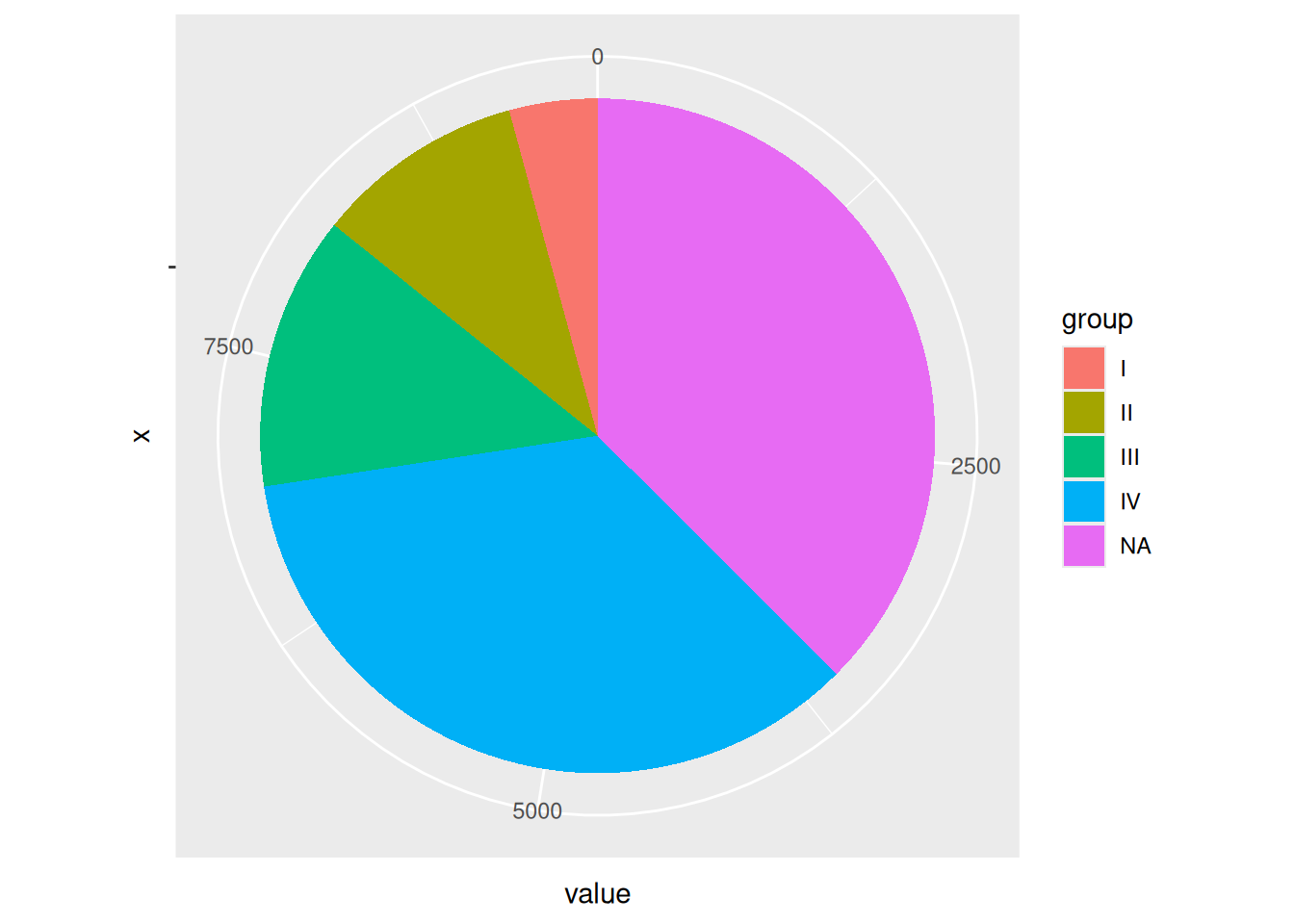
如图是使用ggplot2绘制的饼图,但是坐标标签和刻度并不必要。
2. 简洁饼图
# 使用theme_void()去除grid、backgroundcolor、axis.label等要素
p <- ggplot(data, aes(x = "", y = value, fill = group)) +
geom_col() +
coord_polar(theta = "y") +
theme_void()
p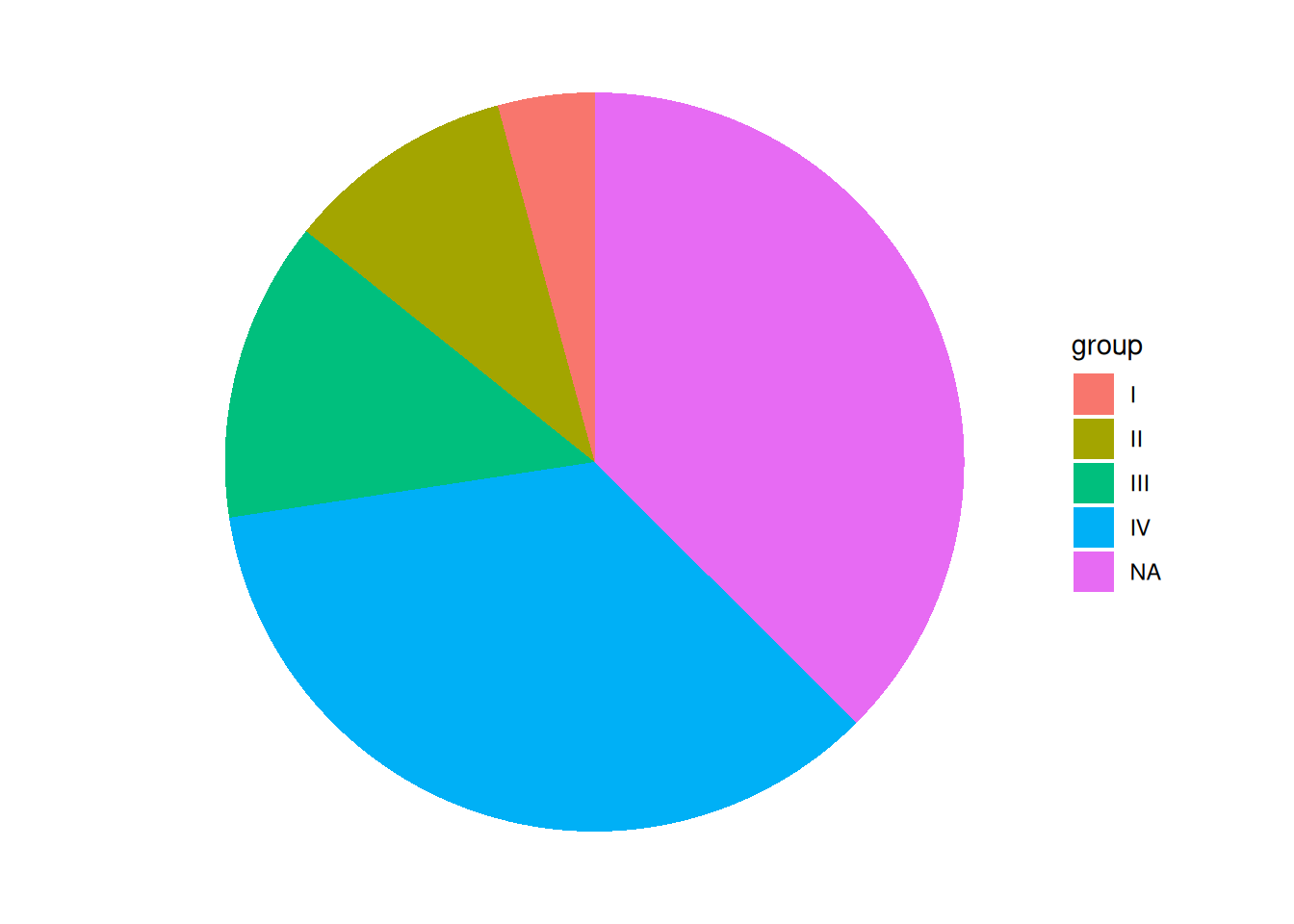
这个饼图去除了grid、backgroundcolor、axis.label等要素,看着更简洁。
3. 自定义颜色
# 使用scale_fill_manual()自定义颜色
p <- ggplot(data, aes(x = "", y = value, fill = group)) +
geom_col() +
coord_polar(theta = "y") +
theme_void() +
scale_fill_manual(values = c("red","blue","purple","pink","grey")) # 自定义颜色
p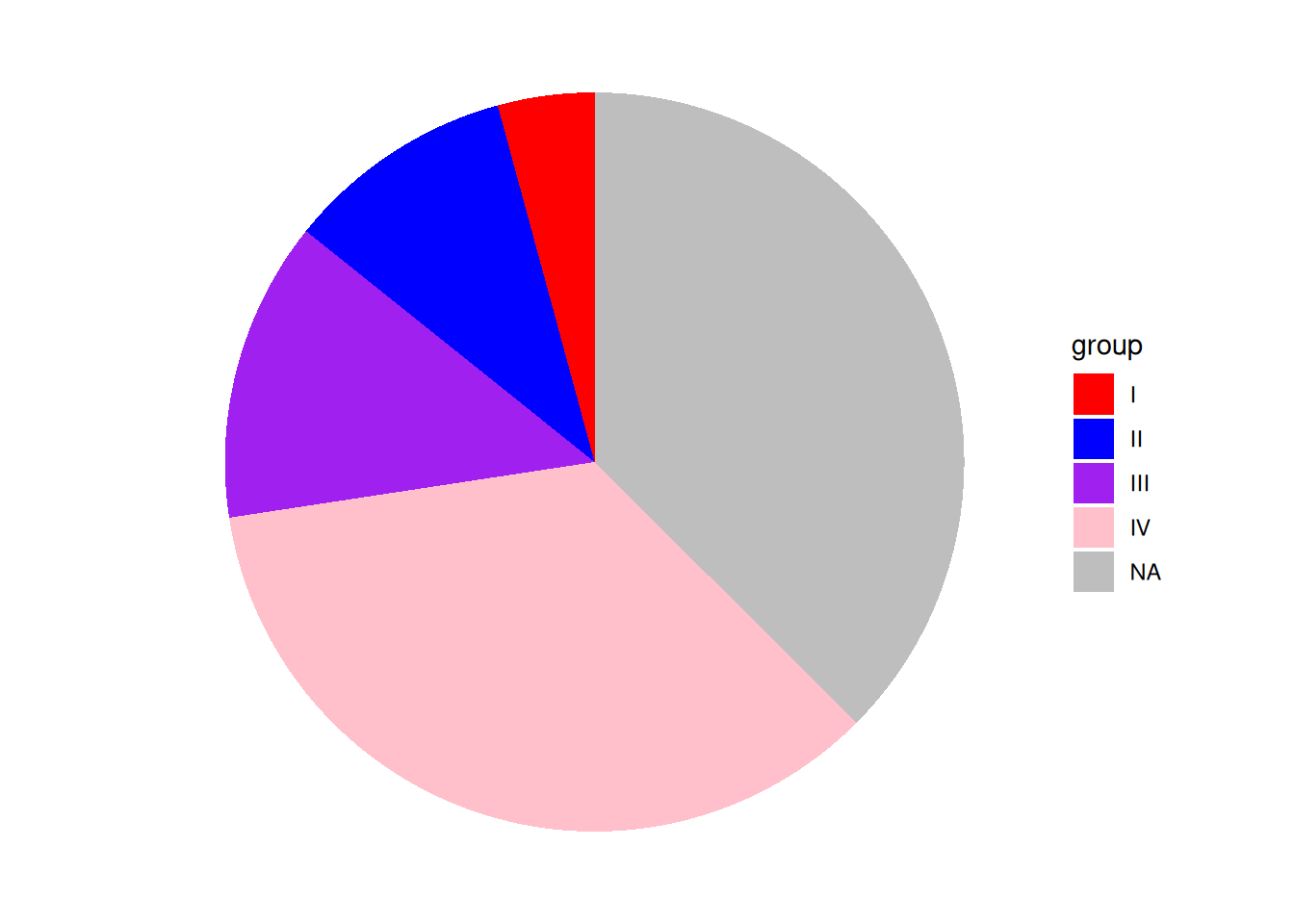
这个饼图使用scale_fill_manual()自定义了颜色。注意不要使用scale_color_manual(),图中的扇形区域的颜色是填充颜色。
4. 添加标签
添加标签前,需要计算标签所在位置,因为绘制饼图中只用了y轴值,所以只用计算y轴坐标。饼图是条形图变换而来的,所以只用计算条形图上每个条形的中心y值即可。比如,group="I",依据条形图I组位置,label_loc就等于下面4组高度+I组高度的一半。
# 计算标签位置
data$label_loc <- NA # 原始数据框加一列标签位置,初始NA
for (i in 1:length(data$group)) { # 循环,计算分组的标签位置
locate <- data$value[i] / 2 # 标签位置是该组中心+下面组的高度,下面组高度用循环计算
if (i < length(data$group)) {
for (j in (i + 1):length(data$group)) {
locate <- locate + data$value[j]
}
}
data$label_loc[i] <- locate # 最终获得该组标签位置
}
# 绘制带标签的饼图
p <- ggplot(data, aes(x = "", y = value, fill = group)) +
geom_col() +
coord_polar(theta = "y") +
theme_void() +
geom_text(aes(y = label_loc, label = group)) + # y是标签的y轴位置,label是标签名称
theme(legend.position = "None") # 由于将分组作为标签,这里去掉图例
p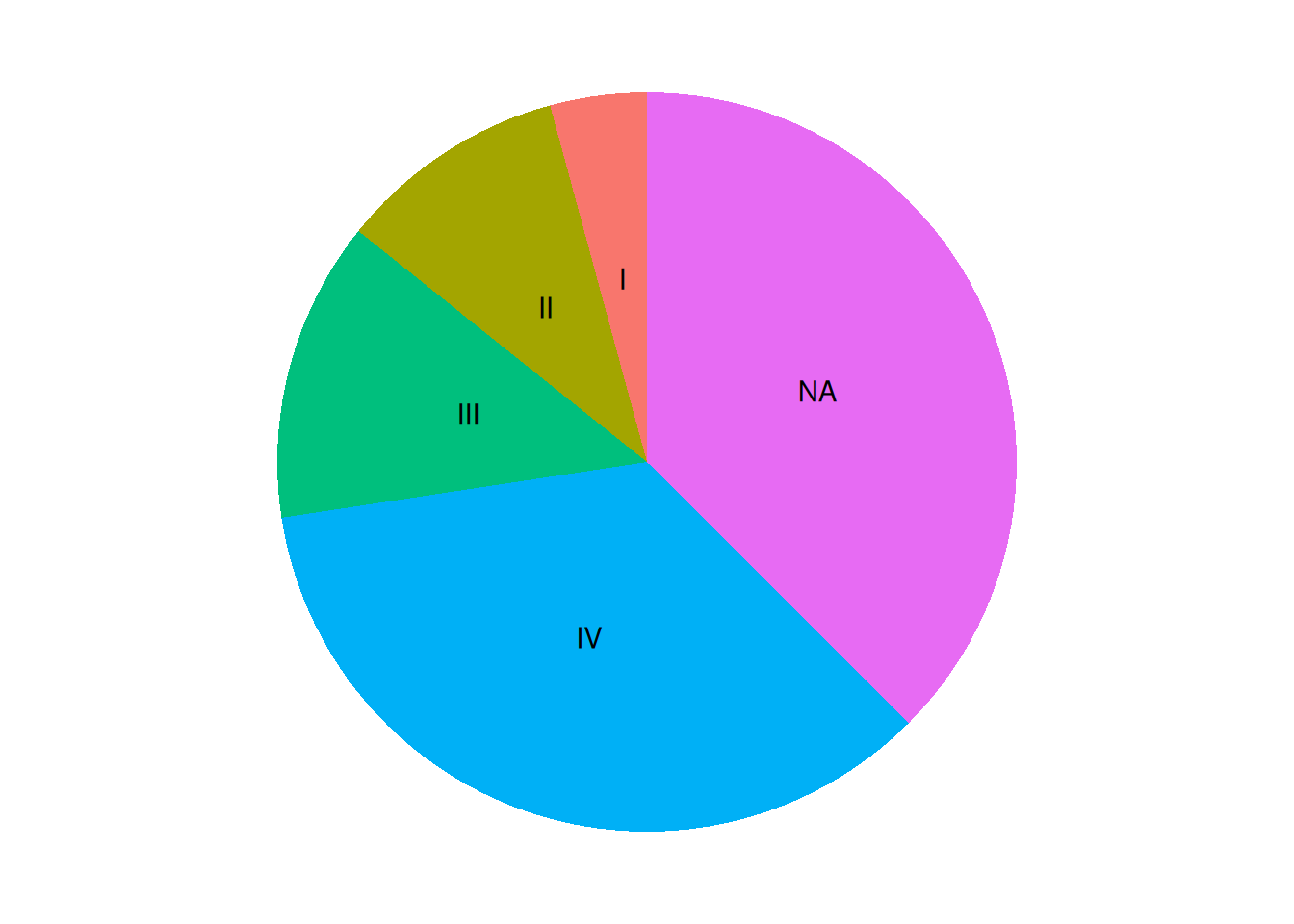
这个饼图成功加上了标签,但是代码有些麻烦。如果使用python或者R的pie()函数绘制会简单很多。
5. 添加百分比标签
# 1.计算标签位置(和上面一致)
data$label_loc <- NA # 原始数据框加一列标签位置,初始NA
for (i in 1:length(data$group)) { # 循环,计算分组的标签位置
locate <- data$value[i] / 2 # 标签位置是该组中心+下面组的高度,下面组高度用循环计算
if (i < length(data$group)) {
for (j in (i + 1):length(data$group)) {
locate <- locate + data$value[j]
}
}
data$label_loc[i] <- locate # 最终获得该组标签位置
}
# 2.计算百分比
data$label <- NA # 原始数据框加一列标签,初始NA
sum <- sum(data$value) # 总和
for (i in 1:length(data$group)) {
data$label[i] <- paste0(round(data$value[i] / sum * 100, 1), "%") # round()保留1位小数,paste0加上百分号
}
# 绘制百分比标签饼图
p <- ggplot(data, aes(x = "", y = value, fill = group)) +
geom_col() +
coord_polar(theta = "y") +
theme_void() +
geom_text(aes(y = label_loc, label = label)) # y是标签的y轴位置,label是百分比标签名称
p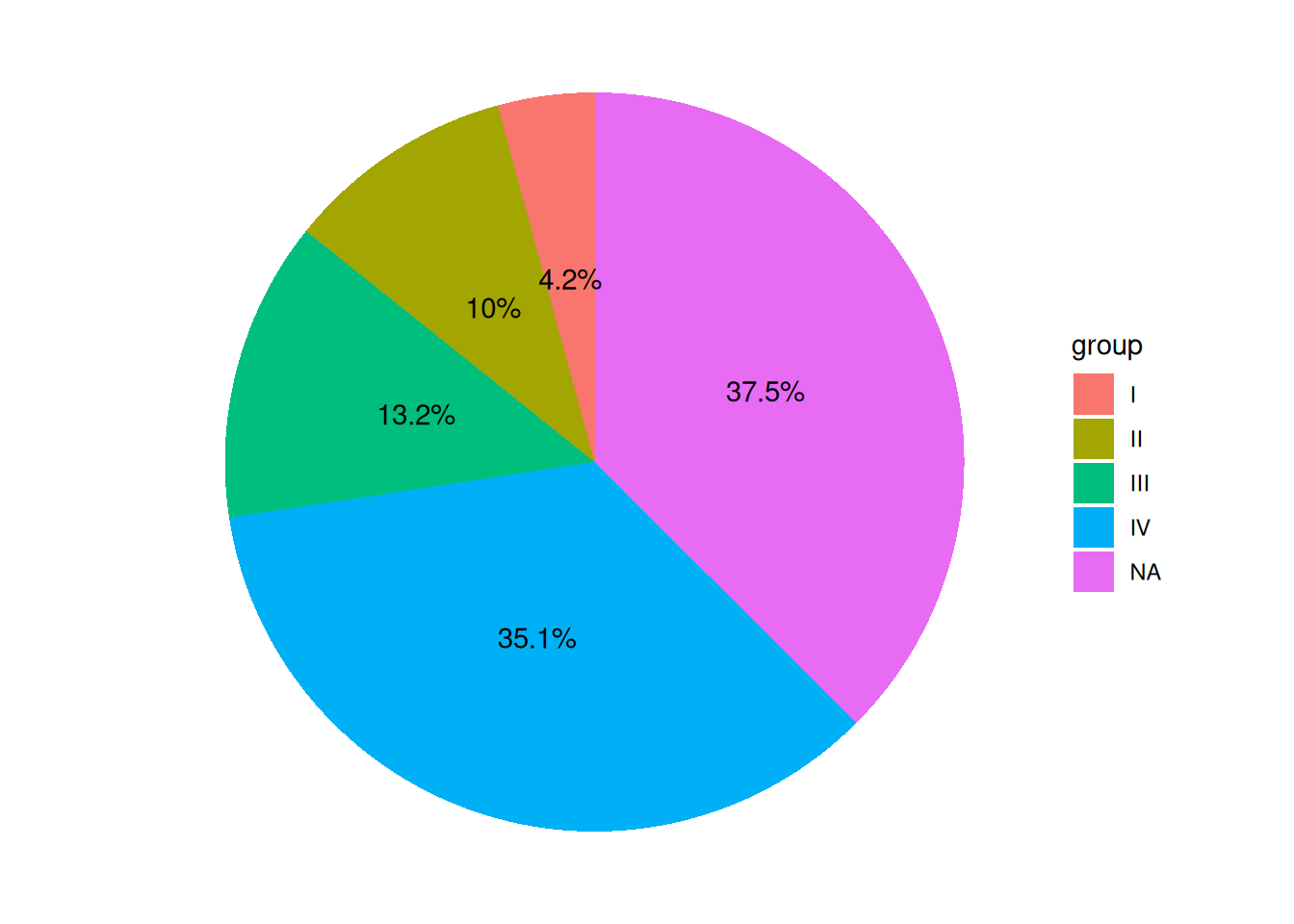
该饼图图例显示分组,标签显示百分比,显得更加美观和直观。
6. 将标签置于饼图外
有时候分组非常多,这个时候将标签放到饼图内,就会显得很拥挤。
# 以下计算百分比标签和标签位置代码没变
# 1.计算标签位置(和上面一致)
data$label_loc <- NA # 原始数据框加一列标签位置,初始NA
for (i in 1:length(data$group)) { # 循环,计算分组的标签位置
locate <- data$value[i] / 2 # 标签位置是该组中心+下面组的高度,下面组高度用循环计算
if (i < length(data$group)) {
for (j in (i + 1):length(data$group)) {
locate <- locate + data$value[j]
}
}
data$label_loc[i] <- locate # 最终获得该组标签位置
}
# 2.计算百分比
data$label <- NA # 原始数据框加一列标签,初始NA
sum <- sum(data$value) # 总和
for (i in 1:length(data$group)) {
data$label[i] <- paste0(round(data$value[i] / sum * 100, 1), "%") # round()保留1位小数,paste0加上百分号
}
# 在geom_text()调节x值的大小即可实现标签的向内(减小x值)向外(增大x值)移动
p <- ggplot(data, aes(x = "", y = value, fill = group)) +
geom_col() +
coord_polar(theta = "y") +
theme_void() +
geom_text(aes(x = rep_len(1.6, length(group)), y = label_loc, label = label)) # y是标签的y轴位置,label是百分比标签名称
p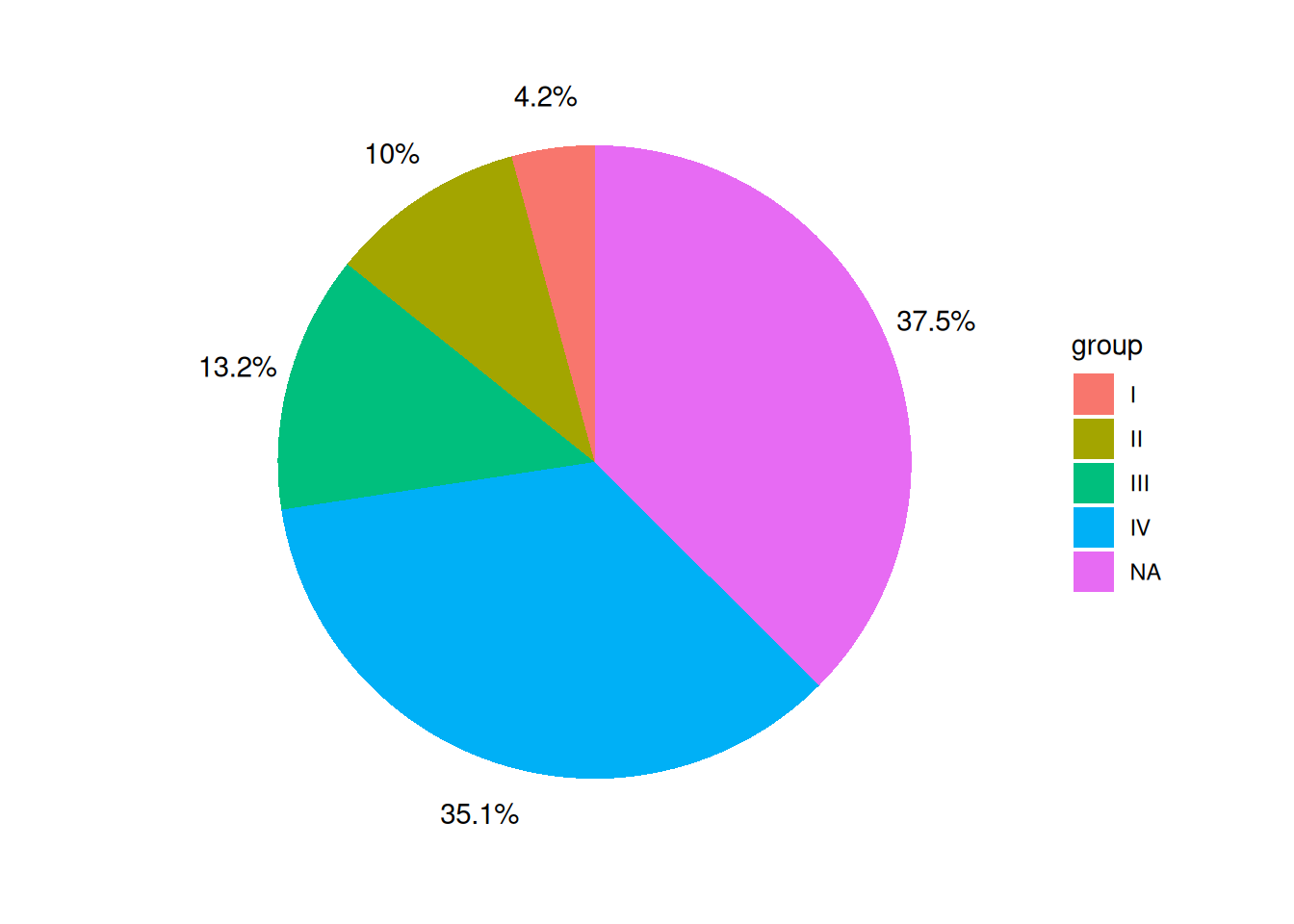
该饼图的标签在饼图外,特别是在分组较多的情况下,饼图会更加美观。
7. 添加标签指向饼图的线段
# 以下计算百分比标签和标签位置代码没变
# 1.计算标签位置(和上面一致)
data$label_loc <- NA # 原始数据框加一列标签位置,初始NA
for (i in 1:length(data$group)) { # 循环,计算分组的标签位置
locate <- data$value[i] / 2 # 标签位置是该组中心+下面组的高度,下面组高度用循环计算
if (i < length(data$group)) {
for (j in (i + 1):length(data$group)) {
locate <- locate + data$value[j]
}
}
data$label_loc[i] <- locate # 最终获得该组标签位置
}
# 2.计算百分比
data$label <- NA # 原始数据框加一列标签,初始NA
sum <- sum(data$value) # 总和
for (i in 1:length(data$group)) {
data$label[i] <- paste0(round(data$value[i] / sum * 100, 1), "%") # round()保留1位小数,paste0加上百分号
}
# 在geom_segment()调节x、xend值的大小即可定义线段,其中x值大于饼图半径,xend值略小于标签的坐标,y,yend仍未为标签位置的向量。
p <- ggplot(data, aes(x = "", y = value, fill = group)) +
geom_col() +
coord_polar(theta = "y") +
theme_void() +
geom_text(aes(x = rep_len(1.6, length(group)), y = label_loc, label = label)) + # y是标签的y轴位置,label是百分比标签名称
geom_segment(aes(
x = rep_len(1.45, length(group)),
xend = rep_len(1.58, length(group)),
y = label_loc, yend = label_loc
))
p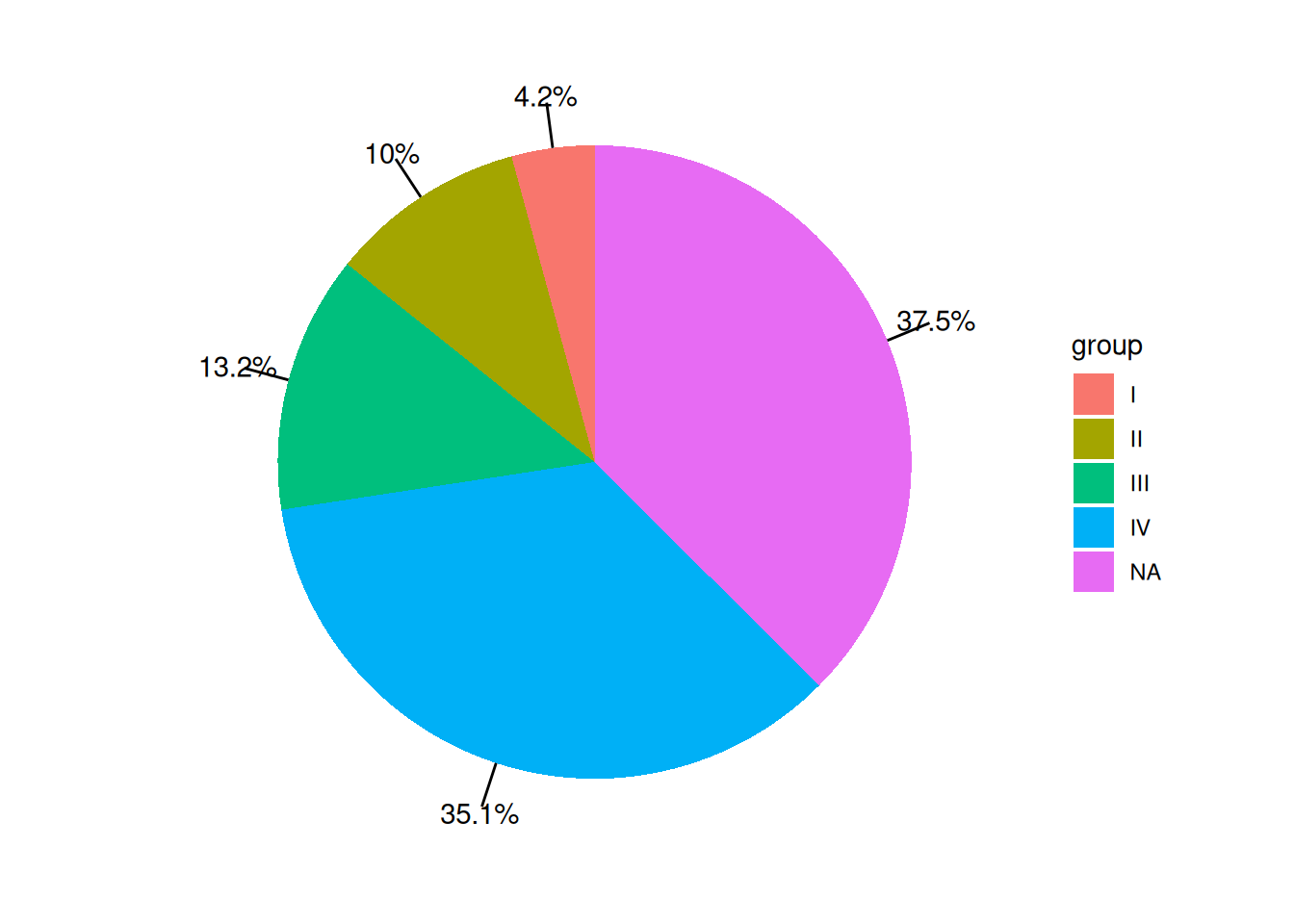
该饼图的标签有相应线段指向饼图特定区域,在分组多的情况下不会弄混。
应用场景
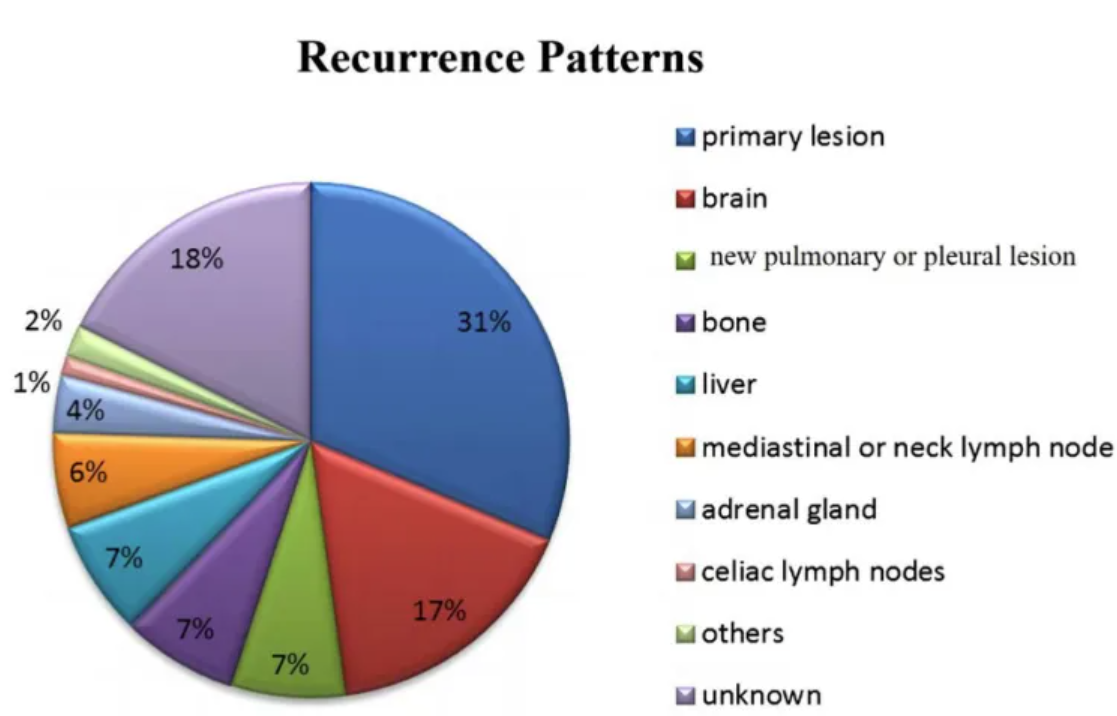
图中显示了小细胞肺癌一线治疗失败后的复发模式主要是原发性病变复发(31%),其次是脑转移(17%)、肺或胸膜转移(7%)、骨转移(7%)、肝转移(7%)、纵隔或颈部淋巴结转移(6%)、肾上腺转移(4%)、腹腔淋巴结转移(1%)、胰腺和肠转移(2%)和未知(18%)。[1]
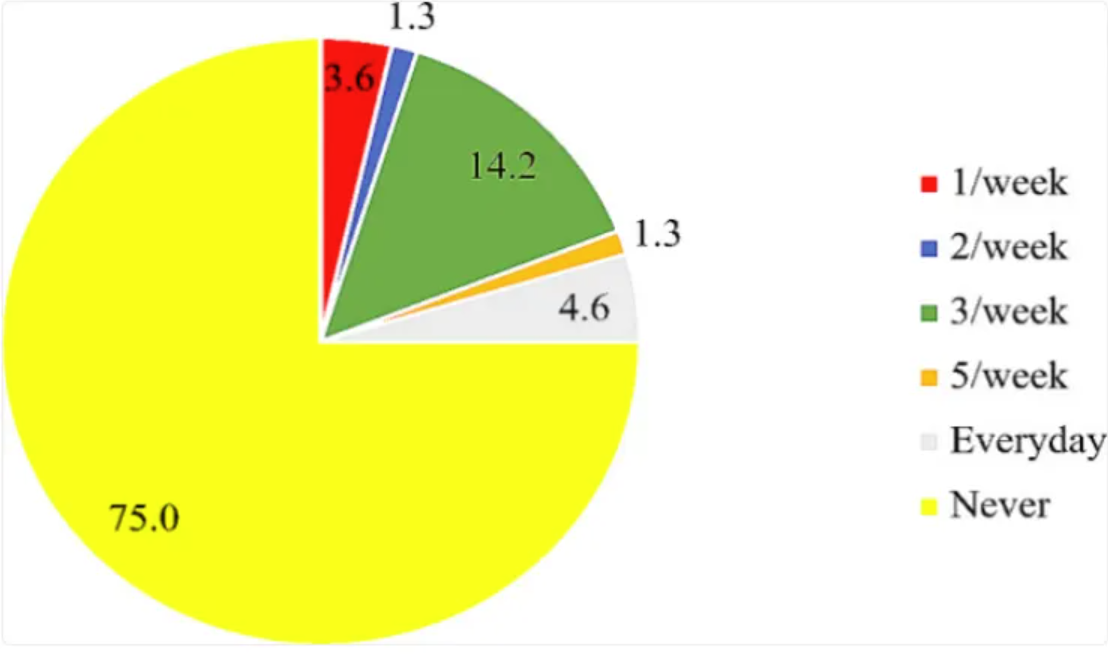
图中显示叶酸补充剂的使用和叶酸强化食品的摄入量相当低,75%的参与者报告从未服用过叶酸补充剂。[2]
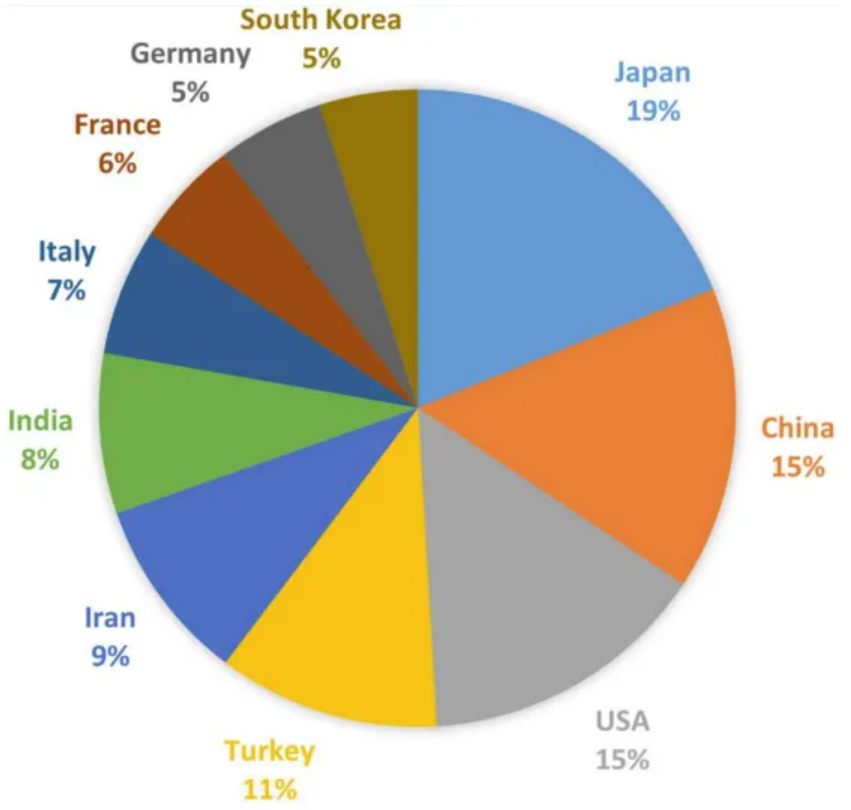
图中表示各国关于TAO的出版物数量,日本发表的相关文章最多(91篇,16.46%),其次是中国(74篇,13.38%)、美国(71篇,12.84%)、土耳其(54篇,9.76%)、伊朗(45篇,8.14%)等。[3]
参考文献
[1] ZHOU Y, WU Z, WANG H, et al. Evaluation of the prognosis in patients with small-cell lung cancer treated by chemotherapy using tumor shrinkage rate-based radiomics[J]. Eur J Med Res, 2024,29(1): 401.
[2] AKWAA H O, IFIE I, NKWONTA C, et al. Knowledge, awareness, and use of folic acid among women of childbearing age living in a peri-urban community in Ghana: a cross-sectional survey[J]. BMC Pregnancy Childbirth, 2024,24(1): 241.
[3] LIU Z, ZHOU C, GUO H, et al. Knowledge Mapping of Global Status and Trends for Thromboangiitis Obliterans: A Bibliometrics and Visual Analysis[J]. J Pain Res, 2023,16: 4071-4087.