# 安装包
if (!requireNamespace("GGally", quietly = TRUE)) {
install.packages("GGally")
}
if (!requireNamespace("hrbrthemes", quietly = TRUE)) {
install.packages("hrbrthemes")
}
if (!requireNamespace("viridis", quietly = TRUE)) {
install.packages("viridis")
}
if (!requireNamespace("dplyr", quietly = TRUE)) {
install.packages("dplyr")
}
if (!requireNamespace("tidyr", quietly = TRUE)) {
install.packages("tidyr")
}
if (!requireNamespace("tibble", quietly = TRUE)) {
install.packages("tibble")
}
if (!requireNamespace("ggbump", quietly = TRUE)) {
install.packages("https://cran.r-project.org/src/contrib/Archive/ggbump/ggbump_0.1.0.tar.gz")
}
if (!requireNamespace("RColorBrewer", quietly = TRUE)) {
install.packages("RColorBrewer")
}
if (!requireNamespace("patchwork", quietly = TRUE)) {
install.packages("patchwork")
}
if (!requireNamespace("MASS", quietly = TRUE)) {
install.packages("MASS")
}
# 加载包
library(GGally)
library(hrbrthemes)
library(viridis)
library(dplyr)
library(tidyr)
library(tibble)
library(ggbump)
library(RColorBrewer)
library(patchwork)
library(MASS)平行坐标图
平行坐标图(parallel coordinate plot)是可视化高维多元数据的一种常用方法,为了显示多维空间中的一组对象,绘制由多条平行且等距分布的轴,并将多维空间中的对象表示为在平行轴上具有顶点的折线。虽然平行折线图属于折线图的特殊类型,但是它和普通的折线图又具有明显的区别。因为平行折线图并不局限于描述某一种或者某几种趋势的变化关系。对于时间序列的不同时间节点、不同梯度的反应浓度等等数值,都可以使用平行坐标图来进行具体数值的描述。
示例
顶点在每一个轴上的位置对应了该对象在该维度上的中的变量数值。此平行坐标图基于Iris数据集,将四个变量(花萼和花瓣的长度和宽度)作为垂直轴,每条线代表一个数据点(花的样本),线条颜色表示花的类别(Setosa、Versicolor、Virginica)。线条穿过每个轴上的点,显示该样本在不同变量上的数值。通过观察这些线的趋势和交叉情况,你可以看到不同类别的花在变量上的差异或相似性。如果线条不交叉,说明组在这些变量上表现相似;如果频繁交叉,说明组在这些变量上差异较大。
环境配置
系统要求: 跨平台(Linux/MacOS/Windows)
编程语言:R
依赖包:
GGally;hrbrthemes;viridis;dplyr;tidyr;tibble;ggbump;RColorBrewer;patchwork;MASS
sessioninfo::session_info("attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.6.0 (2026-04-24)
os Ubuntu 24.04.4 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate C.UTF-8
ctype C.UTF-8
tz UTC
date 2026-05-09
pandoc 3.1.3 @ /usr/bin/ (via rmarkdown)
quarto 1.9.37 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
dplyr * 1.2.1 2026-04-03 [1] RSPM
GGally * 2.4.0 2025-08-23 [1] RSPM
ggbump * 0.1.0 2020-04-24 [1] CRAN (R 4.6.0)
ggplot2 * 4.0.3.9000 2026-05-04 [1] Github (tidyverse/ggplot2@6870419)
hrbrthemes * 0.9.2 2026-05-04 [1] Github (hrbrmstr/hrbrthemes@45ac19c)
MASS * 7.3-65 2025-02-28 [3] CRAN (R 4.6.0)
patchwork * 1.3.2 2025-08-25 [1] RSPM
RColorBrewer * 1.1-3 2022-04-03 [1] RSPM
tibble * 3.3.1 2026-01-11 [1] RSPM
tidyr * 1.3.2 2025-12-19 [1] RSPM
viridis * 0.6.5 2024-01-29 [1] RSPM
viridisLite * 0.4.3 2026-02-04 [1] RSPM
[1] /home/runner/work/_temp/Library
[2] /opt/R/4.6.0/lib/R/site-library
[3] /opt/R/4.6.0/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────数据准备
使用R自带数据集iris和UCSC Xena网站(UCSC Xena (xenabrowser.net))的TCGA-CHOL.methylation450.tsv。
# iris
data_iris <- iris
data_iris <- data_iris %>%
group_by(Species) %>%
sample_n(size = 20, replace = FALSE)
# TCGA-CHOL.methylation450
methylation_raw <- readr::read_tsv("https://bizard-1301043367.cos.ap-guangzhou.myqcloud.com/TCGA-CHOL.methylation450_.tsv")
methylation_selected <- methylation_raw[c(5,7,11),c(4:6)]
rownames(methylation_selected) <- c("cg236", "cg292", "cg658")
colnames(methylation_selected) <- substr(colnames(methylation_selected), 9, 12)
data_tcga <- methylation_selected %>%
rownames_to_column(var = "Composite") %>%
pivot_longer(cols = -Composite, names_to = "sample", values_to = "value")
data_tcga <- data_tcga %>%
mutate(sample = as.numeric(factor(sample))) # 把sample转换为数值可视化
1. 基本绘图
使用ggplot2 包的拓展ggally包的ggparcoord()函数绘制平行图。
1.1 基础平行图
输入数据集必须是具有多个数值变量的数据框,每个变量都用作图表上的垂直轴。这些变量的列数在函数的columns参数中指定。此处,分类变量用于为线条着色,在groupColumn参数中指定。
# 基础平行图
p <- ggparcoord(data_iris, columns = 1:4, groupColumn = 5)
p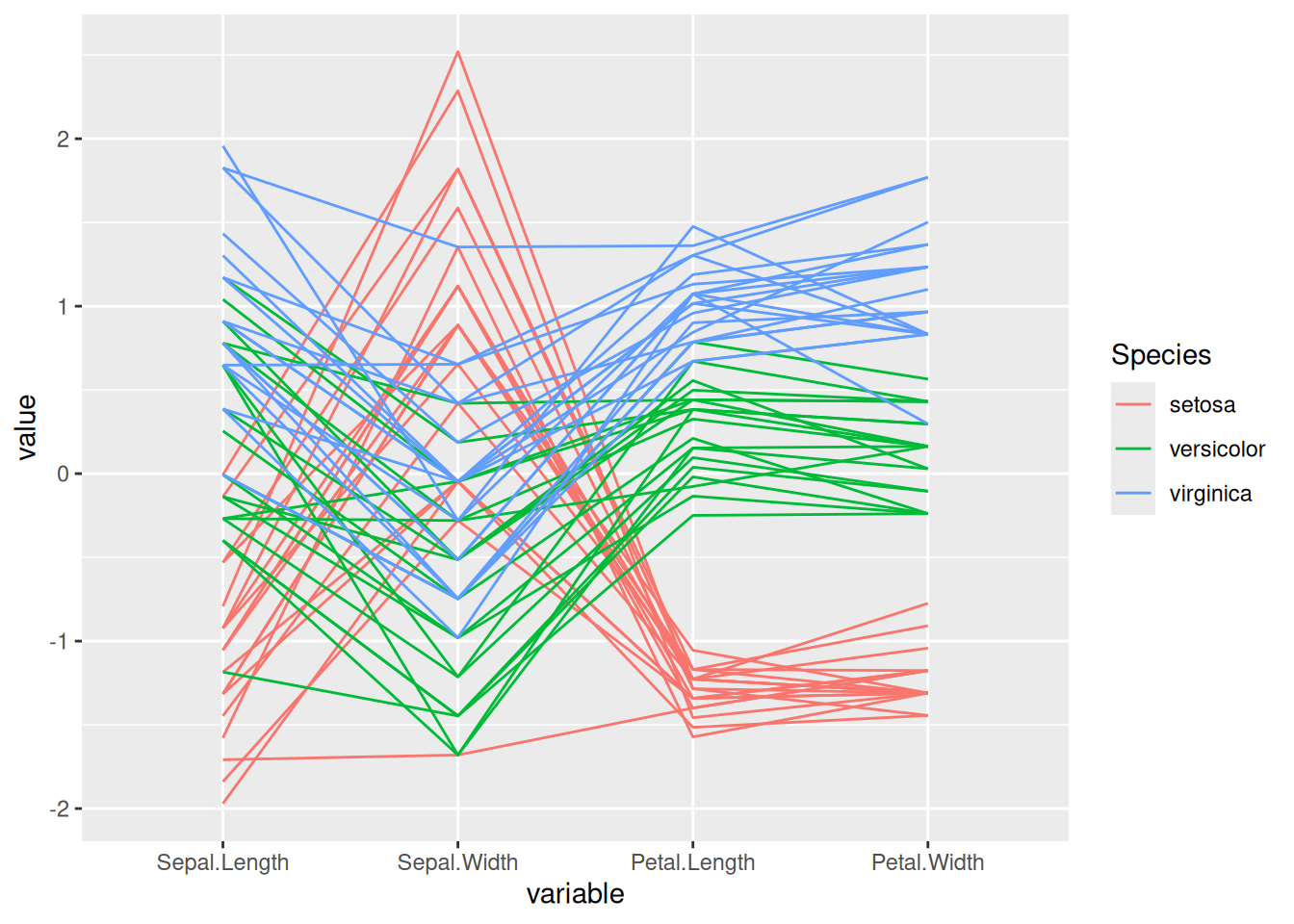
此平行坐标图展示了iris数据集中的花萼长度、花萼宽度、花瓣长度、花瓣宽度之间的关系,每条线代表一个样本,而groupColumn指定的花的类别用于区分线的颜色。
1.2 自定义颜色、主题、整体外观
这张图表与上一张图表基本相同,但有以下自定义:
- 使用
viridis包改变调色板颜色 - 使用
title添加标题,并自定义theme - 使用
showPoints添加点 - 使用
alphaLines改变了线条透明度 -
theme_ipsum()使用主题
# 自定义颜色、主题、整体外观
p <- ggparcoord(data_iris,
columns = 1:4, groupColumn = 5, order = "anyClass",
showPoints = TRUE,
title = "Parallel Coordinate Plot for the Iris Data",
alphaLines = 0.3) +
scale_color_viridis(discrete=TRUE) +
theme_ipsum()+
theme(plot.title = element_text(size=10))
p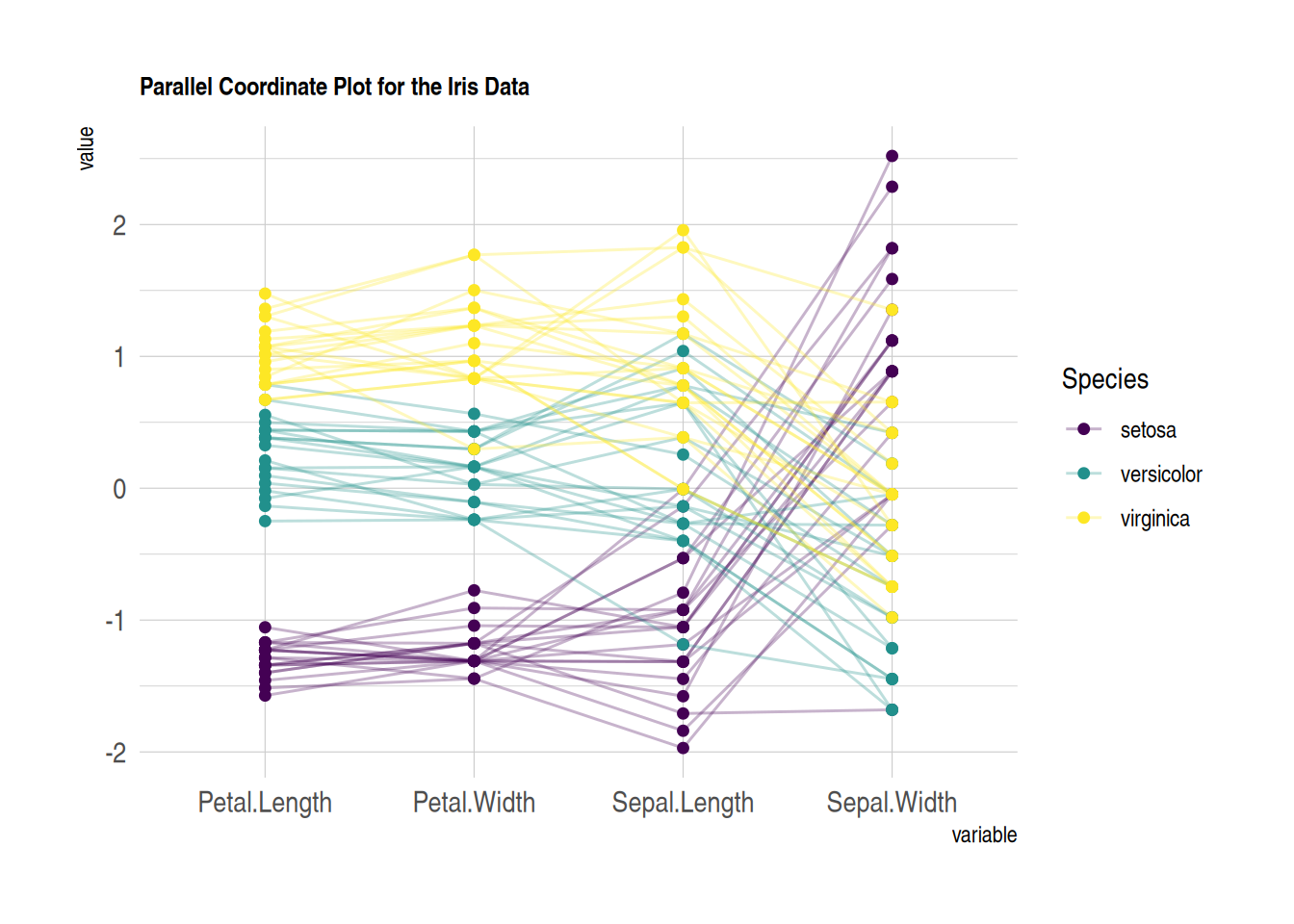
此平行坐标图展示了iris数据集中的花萼长度、花萼宽度、花瓣长度、花瓣宽度之间的关系,自定义图片使图片更加美观易读。
1.3 标准化
标准化转换原始数据,使其可以与其他变量进行比较。这是比较没有相同单位的变量的关键步骤。
ggally包提供了一个比例参数scale。下面在同一数据集上应用了四个可能的选项:
-
globalminmax→ 无标准化 -
uniminmax→ 标准化为最小值 = 0 和最大值 = 1 -
std→ 单变量标准化(减去平均值并除以标准差) -
center→ 标准化和中心变量(变量的中心位置都被调整为零)
# 无标准化
p1 <- ggparcoord(data_iris,
columns = 1:4, groupColumn = 5, order = "anyClass",
scale="globalminmax",
showPoints = TRUE,
title = "No scaling",
alphaLines = 0.3
) +
scale_color_viridis(discrete=TRUE) +
theme_ipsum()+
theme(
legend.position="none",
plot.title = element_text(size=13)
) +
xlab("")
# 标准化为最小值 = 0 和最大值 = 1
p2 <- ggparcoord(data_iris,
columns = 1:4, groupColumn = 5, order = "anyClass",
scale="uniminmax",
showPoints = TRUE,
title = "Standardize to Min = 0 and Max = 1",
alphaLines = 0.3
) +
scale_color_viridis(discrete=TRUE) +
theme_ipsum()+
theme(
legend.position="none",
plot.title = element_text(size=13)
) +
xlab("")
# 单变量标准化
p3 <- ggparcoord(data_iris,
columns = 1:4, groupColumn = 5, order = "anyClass",
scale="std",
showPoints = TRUE,
title = "Normalize univariately (substract mean & divide by sd)",
alphaLines = 0.3
) +
scale_color_viridis(discrete=TRUE) +
theme_ipsum()+
theme(
legend.position="none",
plot.title = element_text(size=13)
) +
xlab("")
# 标准化和中心变量
p4 <- ggparcoord(data_iris,
columns = 1:4, groupColumn = 5, order = "anyClass",
scale="center",
showPoints = TRUE,
title = "Standardize and center variables",
alphaLines = 0.3
) +
scale_color_viridis(discrete=TRUE) +
theme_ipsum()+
theme(
legend.position="none",
plot.title = element_text(size=13)
) +
xlab("")
p1 + p2 + p3 + p4 + plot_layout(ncol = 2)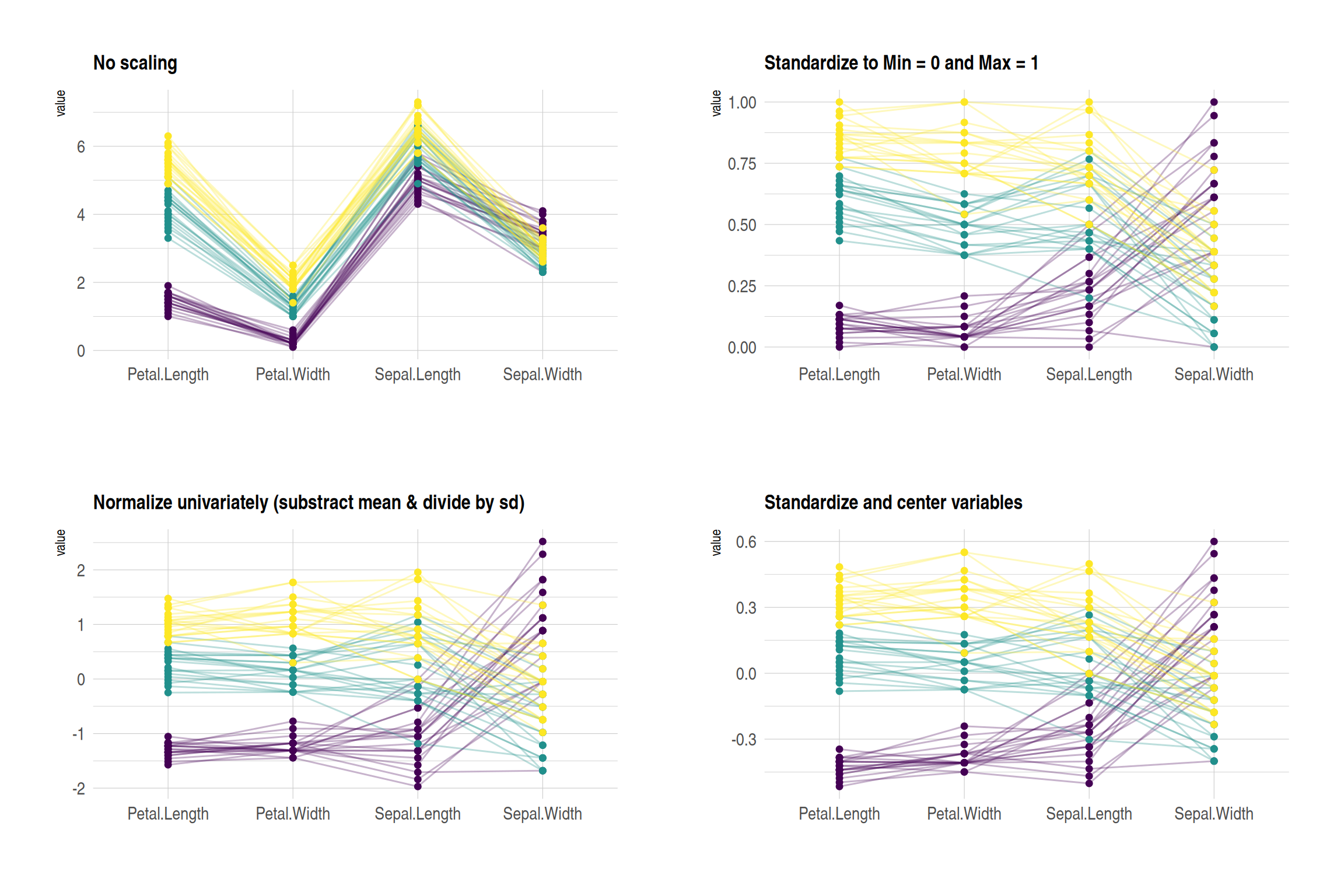
这四个图展示了不同的标准化方法对iris数据集的影响:
- 无标准化 (No scaling):展示原始数据,每个变量保留其原始范围,数值范围差异较大的变量更显著。
- 最小值 = 0 和最大值 = 1 (Standardize to Min = 0 and Max = 1):所有变量的值被缩放到相同范围(0到1),便于比较不同变量的变化趋势。
- 单变量标准化 (Normalize univariately):每个变量被标准化为均值为0、标准差为1,突出数据的相对差异。
- 标准化和中心变量 (Standardize and center variables):数据经过均值中心化,突出不同组在每个变量上的相对差异。
这些图用颜色区分不同的花种,线条表示每个样本在不同变量上的值。
1.4 突出显示组
如果对某个特定群体感兴趣,可以通过改变不同分类的颜色突出显示:
# 突出显示组
p <- data_iris %>%
arrange(desc(Species)) %>%
ggparcoord(
columns = 1:4, groupColumn = 5, order = "anyClass",
showPoints = TRUE,
title = "Original",
alphaLines = 1
) +
scale_color_manual(values=c( "#69b3a2", "#E8E8E8", "#E8E8E8") ) + # 通过改变不同分类的颜色来突出特定群体
theme_ipsum()+
theme(
legend.position="Default",
plot.title = element_text(size=10)
) +
xlab("")
p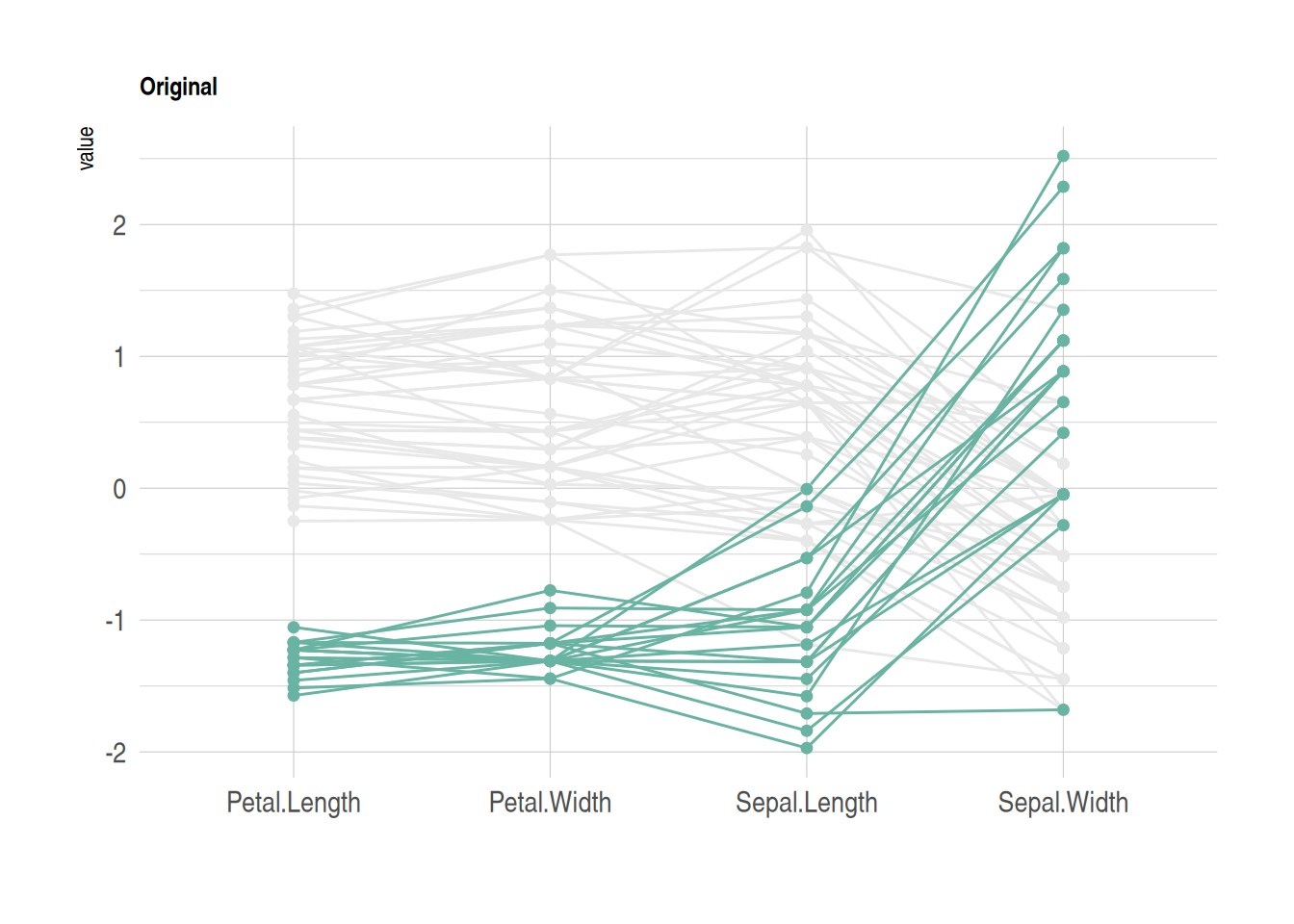
这个图展示了iris数据集中不同花种在四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)上的表现。图中使用平行坐标图来显示每个样本在这些变量上的数值。通过按花种降序排列并着色,图中用绿色突出了Setosa花种,其余两种花种以灰色表示。线条代表样本,显示它们在不同特征上的数值变化。
2. MASS 包
2.1 基础平行图(MASS 包)
使用MASS包构建平行坐标图。请注意,使用ggplot2可能是更好的选择。
my_colors <- colors()[as.numeric(data_iris$Species) * 11]
parcoord(data_iris[, c(1:4)], col = my_colors)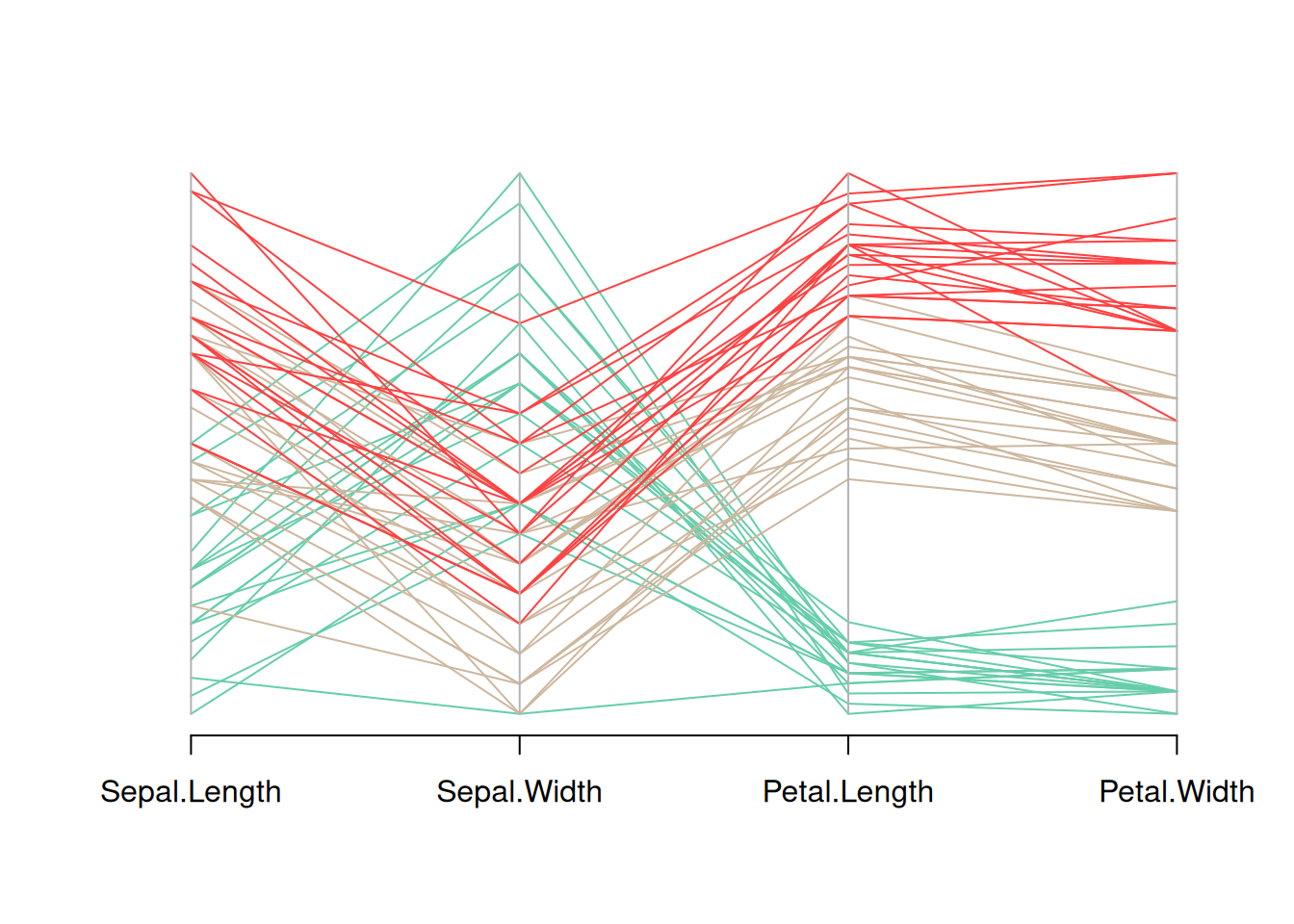
这个图是Iris数据集的平行坐标图,显示了数据集中四个变量(花萼长度、花萼宽度、花瓣长度和花瓣宽度)的分布。不同花种用不同颜色区分,通过观察不同颜色线条的走势,可以看到不同花种在这些变量上的模式差异。
2.2 添加图例
使用legend()添加图例。
my_colors <- colors()[as.numeric(data_iris$Species) * 11]
parcoord(data_iris[, c(1:4)], col = my_colors)
legend("topright",
legend = levels(data_iris$Species),
col = unique(my_colors),
pch = 1) # 添加图例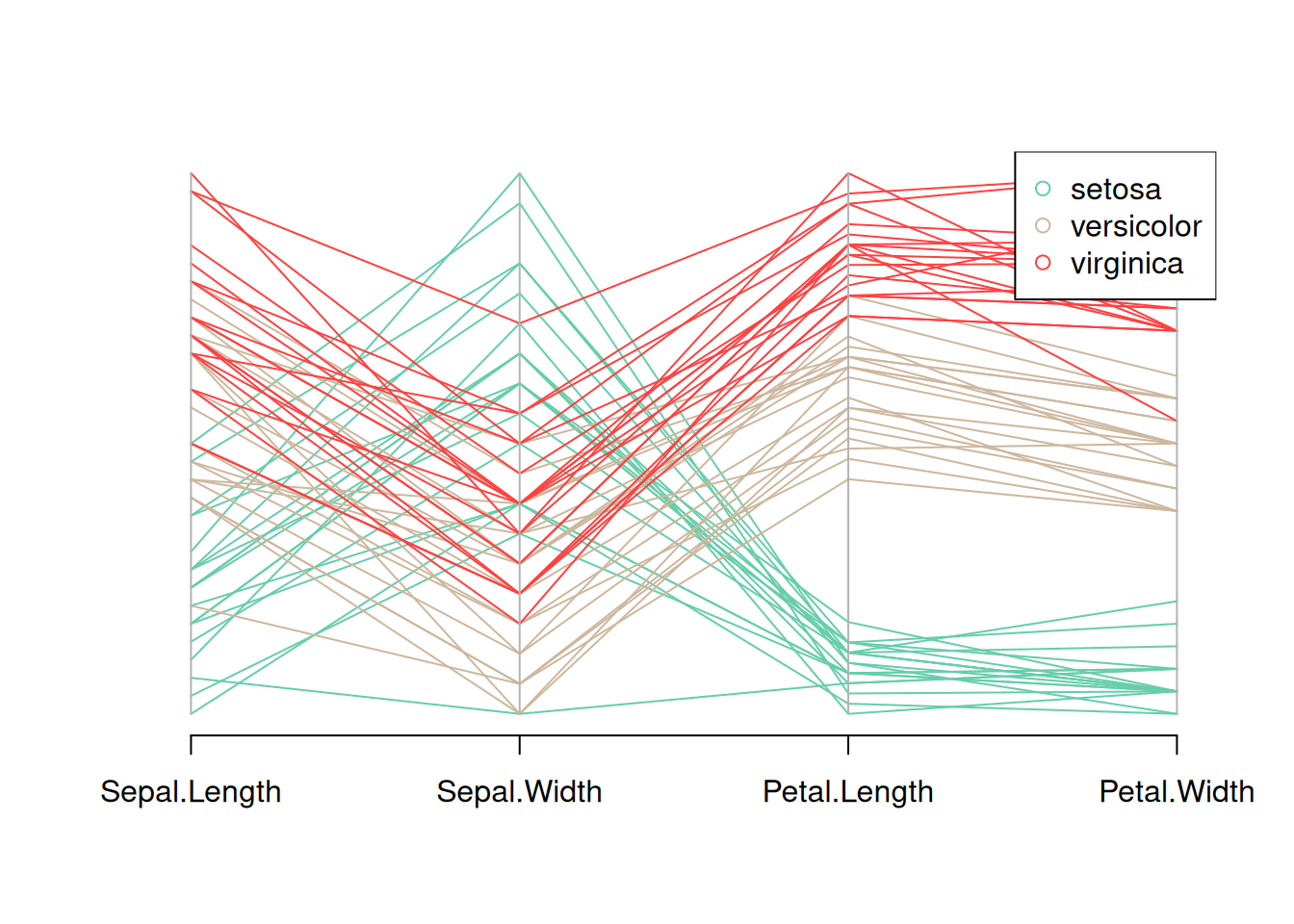
这个图是Iris数据集的平行坐标图,显示了数据集中四个变量(花萼长度、花萼宽度、花瓣长度和花瓣宽度)的分布。不同花种用不同颜色区分,显示了图例,通过观察不同颜色线条的走势,可以看到每个花种在这些变量上的模式差异。
2.3 重新排序变量
在平行坐标图中找到最佳变量顺序非常重要。要更改它,只需更改输入数据集中的顺序即可。
palette <- brewer.pal(3, "Set1")
my_colors <- palette[as.numeric(data_iris$Species)]
parcoord(data_iris[,c(1,3,4,2)] , col= my_colors)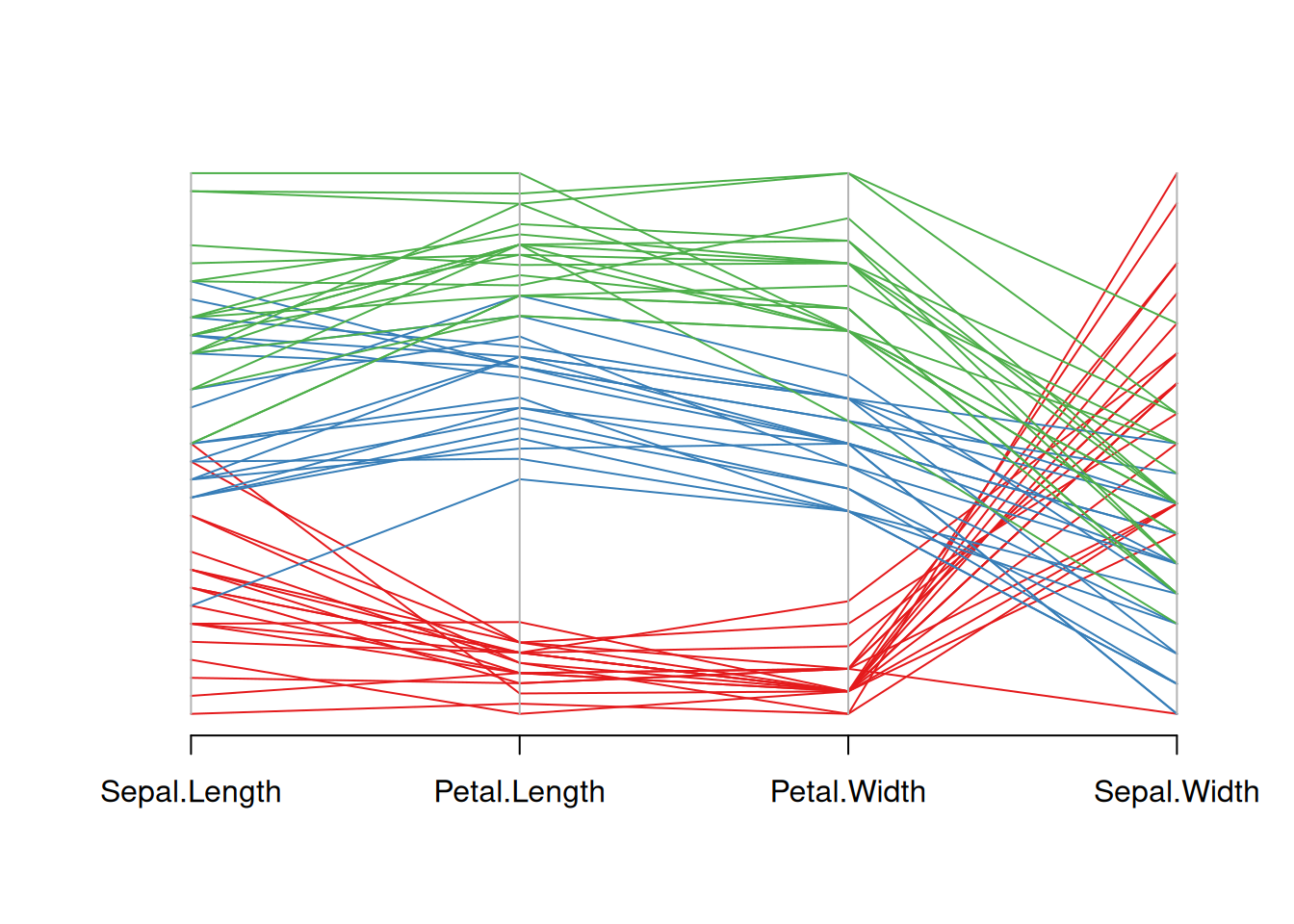
这个图是Iris数据集的平行坐标图,展示了花萼长度、花瓣长度、花瓣宽度和花萼宽度这四个变量的分布。不同花种用三种不同颜色表示,通过观察颜色线条的变化,可以看出不同花种在这些变量上的差异趋势。更改输入数据集中的顺序对变量进行重新排序。
2.4 突出显示组
如果对某个特定群体感兴趣,可以改变颜色,突出显示此分组。
isSetosa <- ifelse(data_iris$Species=="setosa","red","grey")
parcoord(data_iris[,c(1,3,4,2)] , col=isSetosa)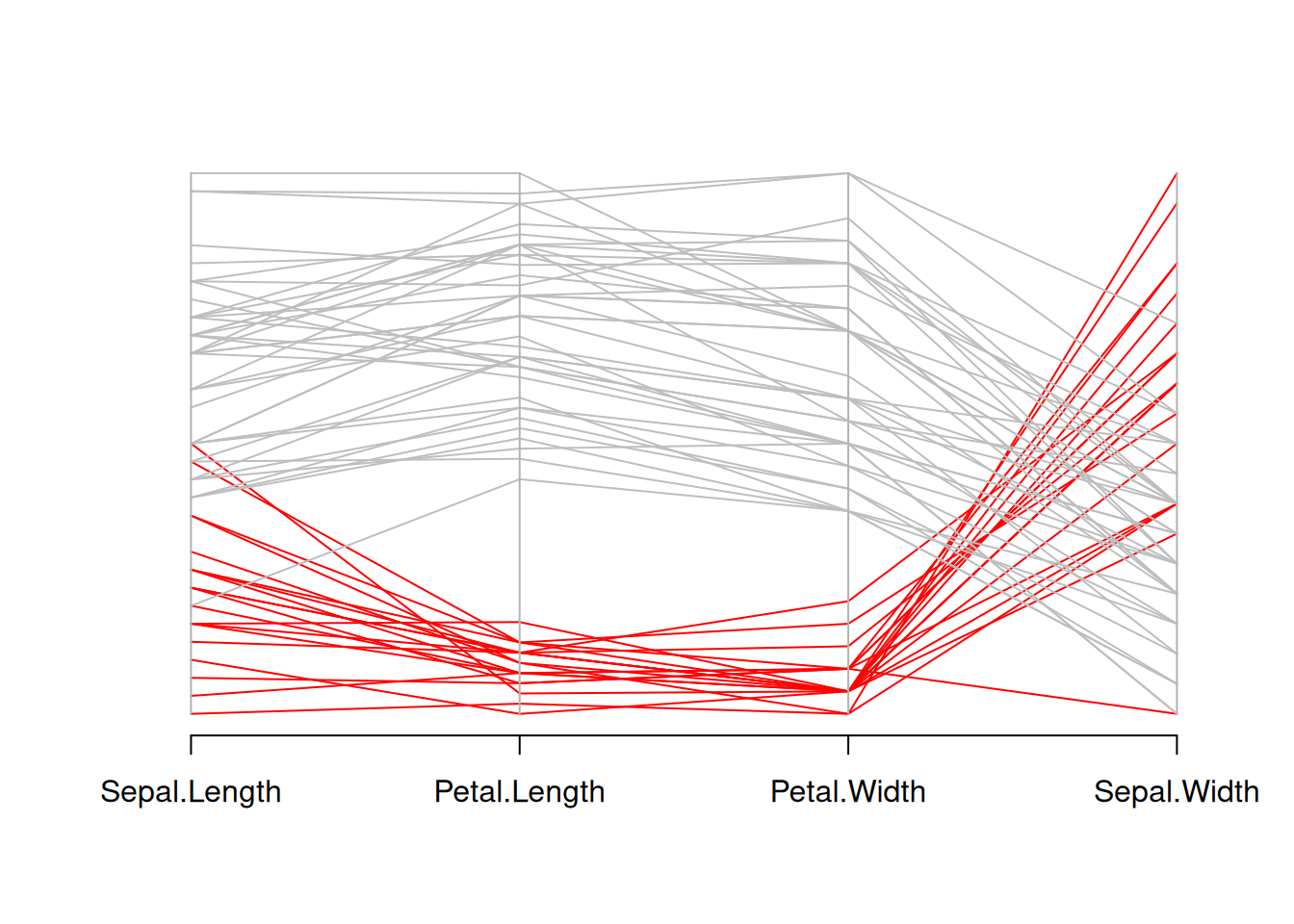
这个图是Iris数据集的平行坐标图,其中setosa花种用红色显示,其他花种用灰色显示。通过这个图,可以直观地看到setosa与其他花种在花萼长度、花瓣长度、花瓣宽度和花萼宽度上的分布差异。
3. 凹凸图
凹凸图是一种可以直观地展示变化趋势的图表,常用于对比不同类别的数据。
3.1 基础凹凸图
p <- ggplot(data_tcga, aes(x = sample, y = value, color = Composite)) +
geom_bump(size = 2) +
theme_minimal()
p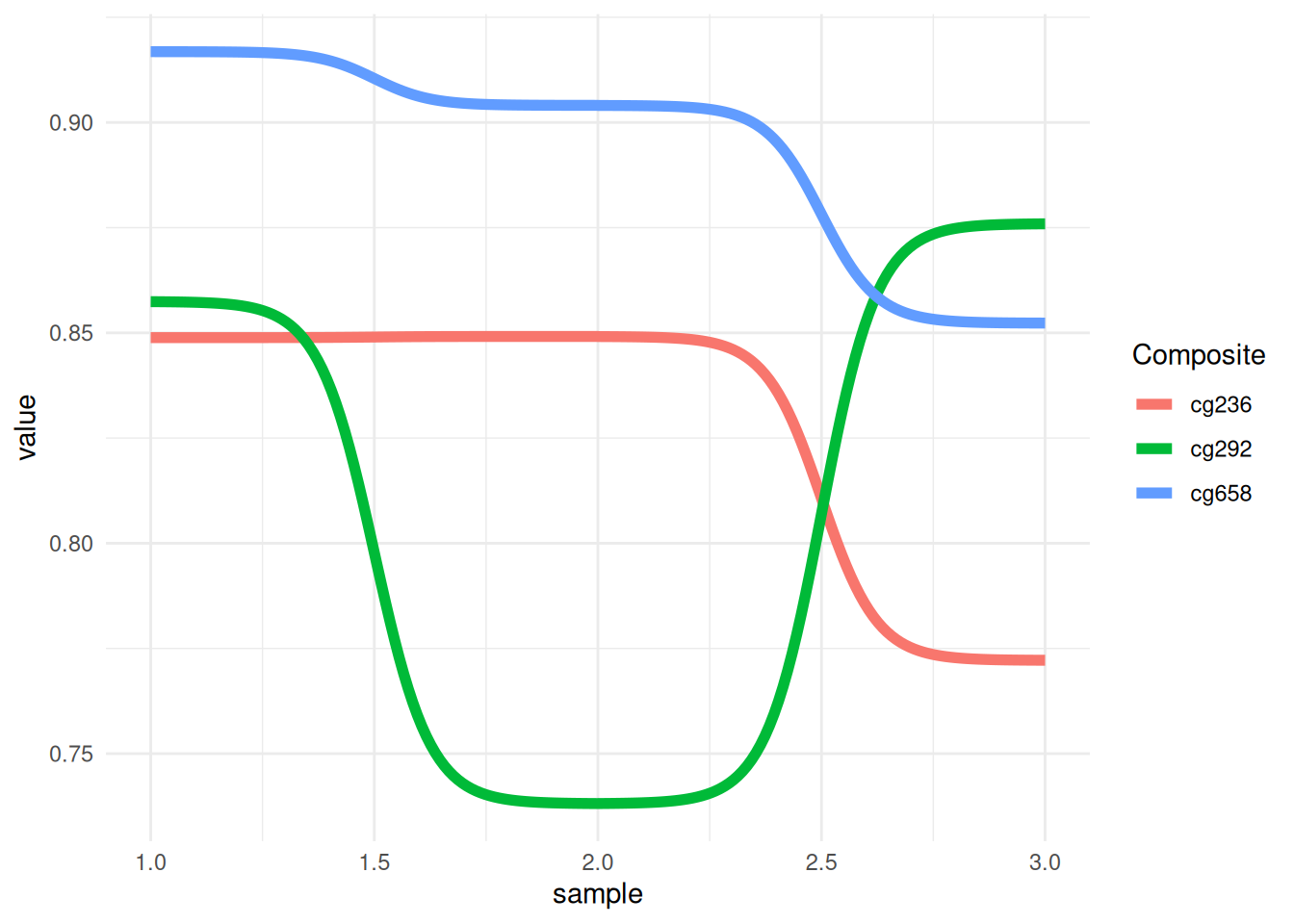
这个图展示了不同“Composite”(cg236、cg292、cg658)在不同“sample”中的甲基化数值变化趋势。通过颜色区分不同的“Composite”组,线条表示每组在不同样本中的表现。观察线条的起伏可以看出每组在各个样本中数值的变化趋势和相对差异。
3.2 更改颜色
可以将单个点添加到凹凸图。这可以通过添加geom_point()图层来实现。使用ggbump包绘制凹凸图。
p <- ggplot(data_tcga, aes(x = sample, y = value, color = Composite)) +
geom_bump(size = 2) +
geom_point(size = 6) +
scale_color_brewer(palette = "Paired") +
theme_minimal()
p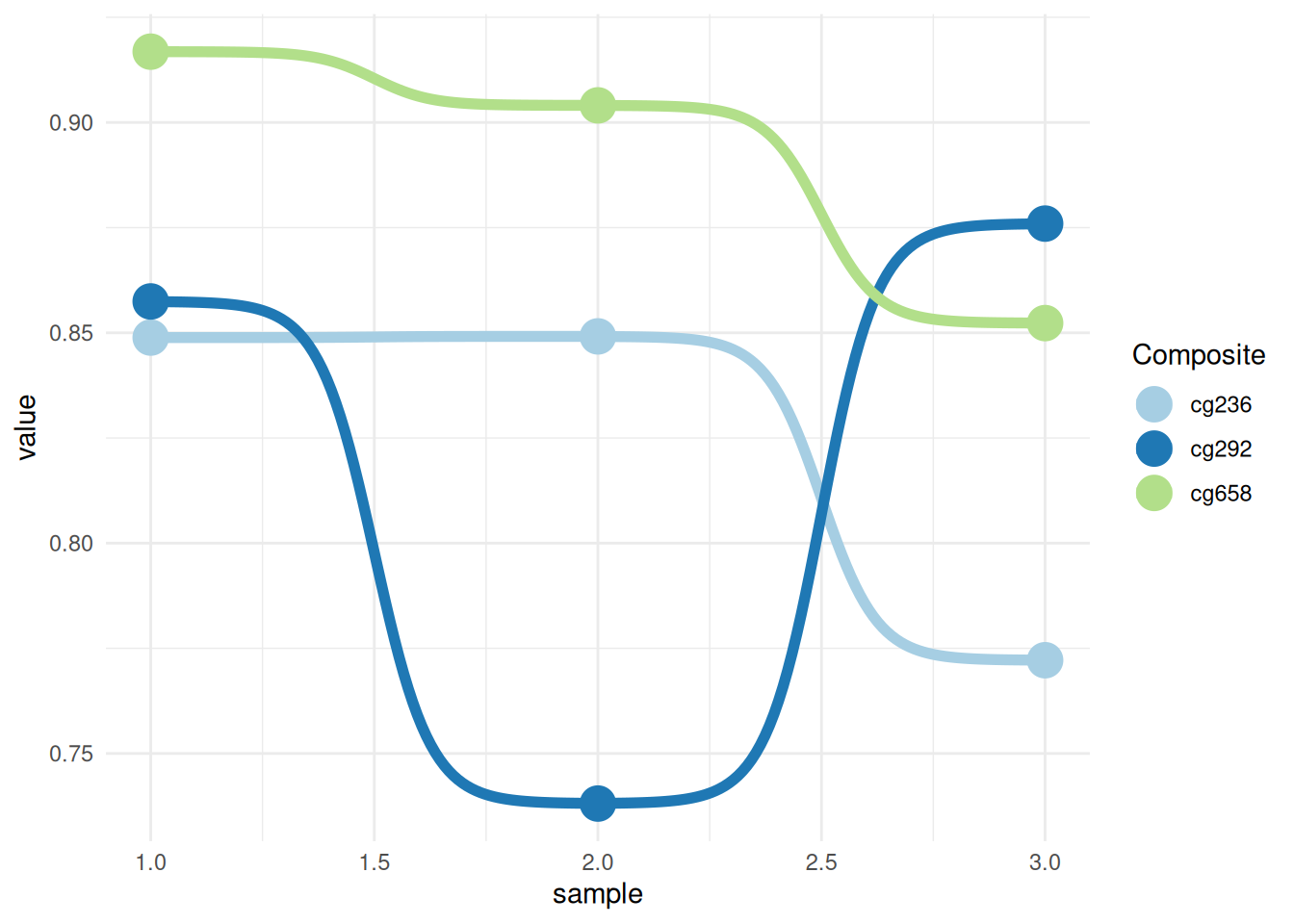
这个图展示了不同“Composite”(cg236、cg292、cg658)在不同“sample”中的甲基化数值变化趋势。通过颜色区分不同的“Composite”组,线条表示每组在不同样本中的表现。观察线条的起伏可以看出每组在各个样本中数值的变化趋势和相对差异。通过添加点和改变颜色使图片更加美观易读。
3.3 添加标签和标题
geom_text()和函数labs()可用于向图表添加标签和标题。
p <- ggplot(data_tcga, aes(x = sample, y = value, color = Composite)) +
geom_bump(size = 2) +
geom_point(size = 6) +
geom_text(aes(label = Composite), nudge_y = -0.01, fontface = "bold", size=3) +
scale_color_brewer(palette = "Paired") +
theme_minimal() +
labs(title = "Bump Plot of Methylation Values",
x = "Sample", y = "Value")
p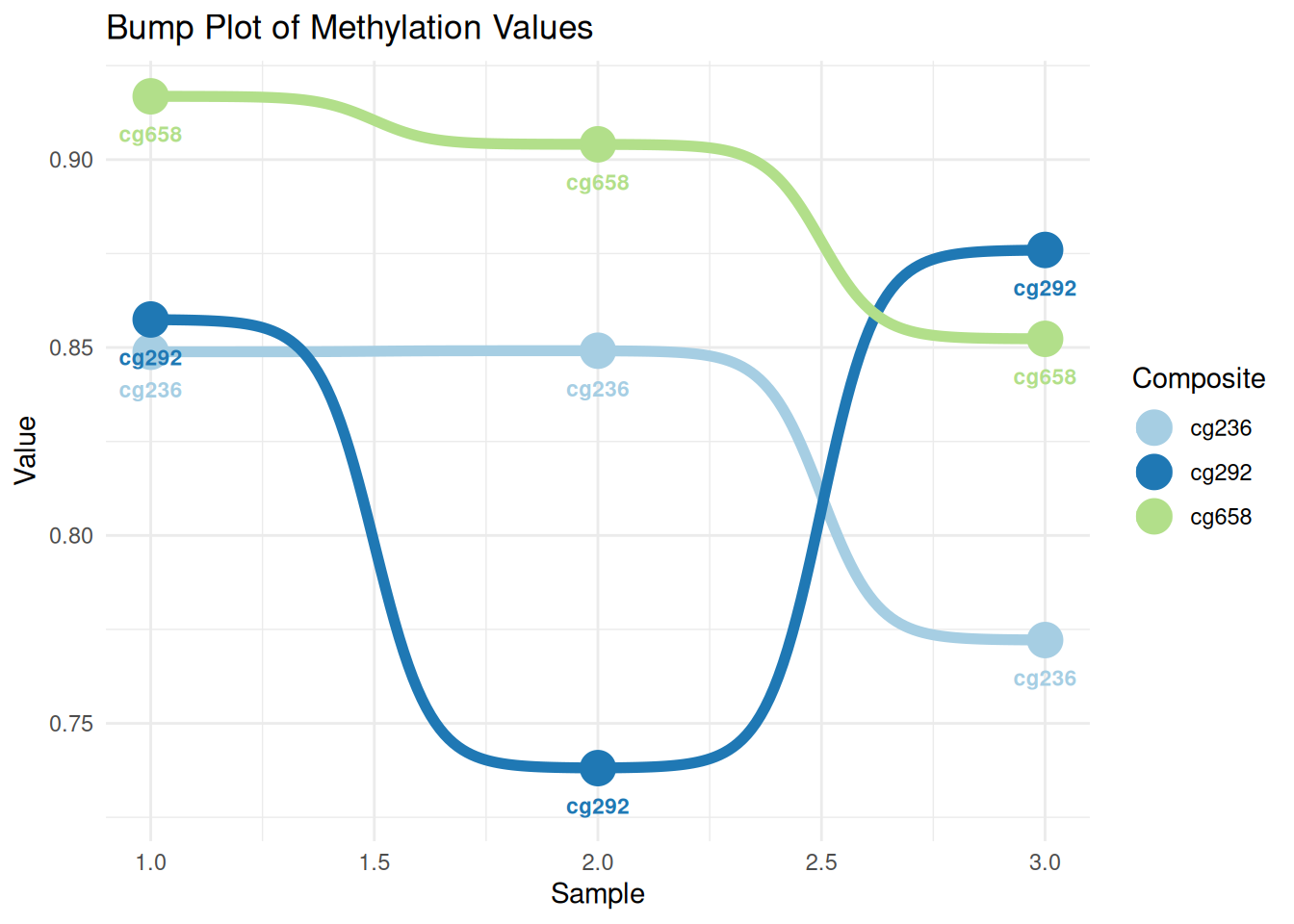
这个图展示了不同“Composite”(cg236、cg292、cg658)在不同“sample”中的甲基化值变化。线条表示每个“Composite”在不同样本中的数值趋势,点表示具体数值,标签标出“Composite”的名字。颜色区分不同的“Composite”,通过样本间的线条起伏可以看出它们的数值变化。
应用场景
1. 基础平行图
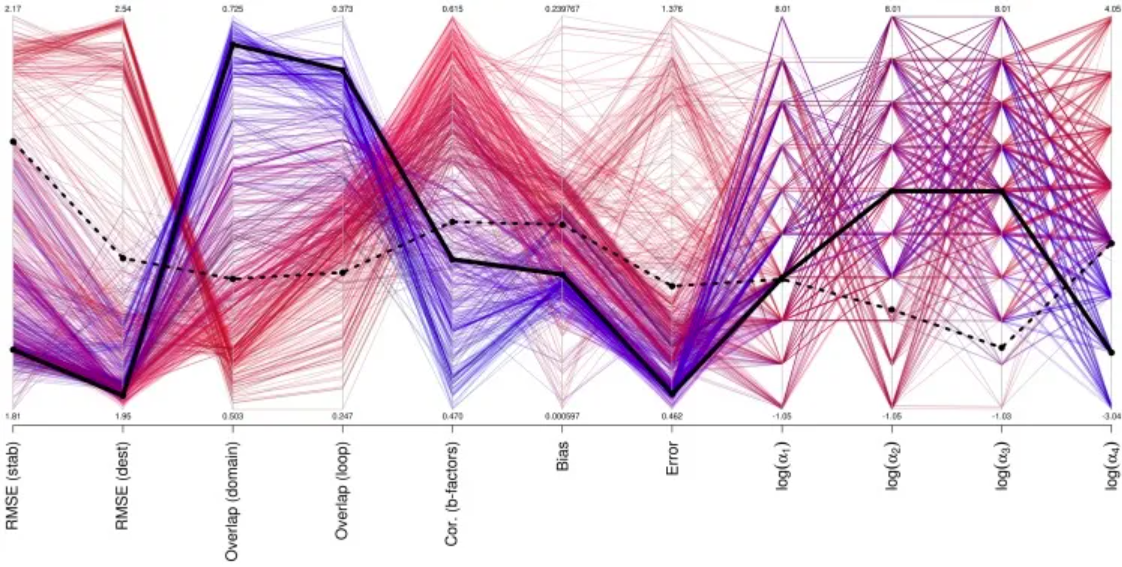
不同参数集对突变、b 因子和运动预测的性能。 [1]
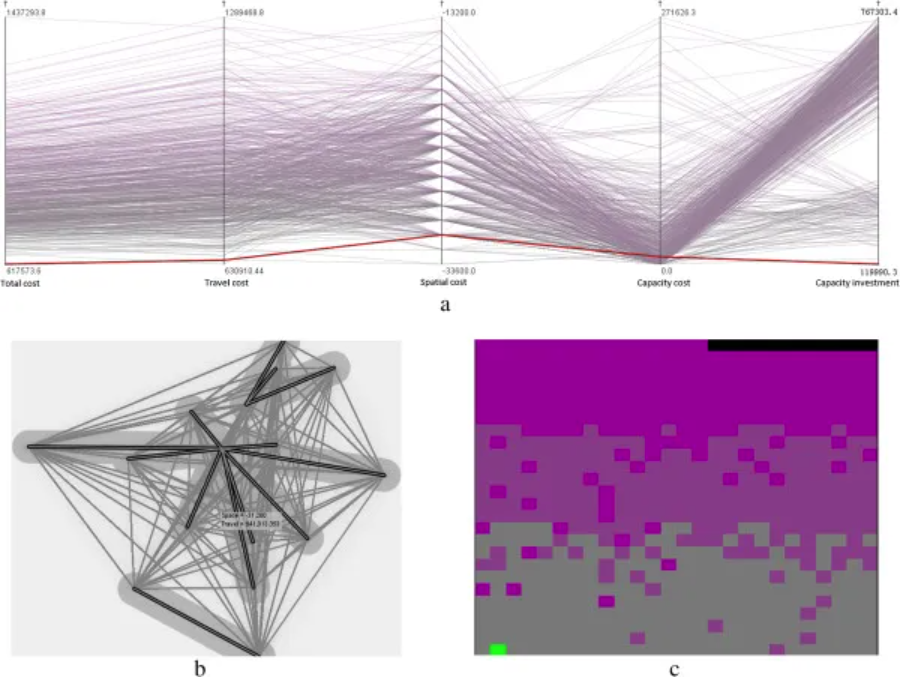
使用 (a) 平行坐标图、(b) 二元地理地图和 (c) 空间填充栅格在混合交通网络中选择最佳医疗保健中心。(注:两个变量,即总成本和差旅成本,在空间填充栅格中可视化。总成本用从灰色到紫色的色带表示,差旅成本用扫描线从左到右、从下到上升序排序。 [2]
2. 分面平行图
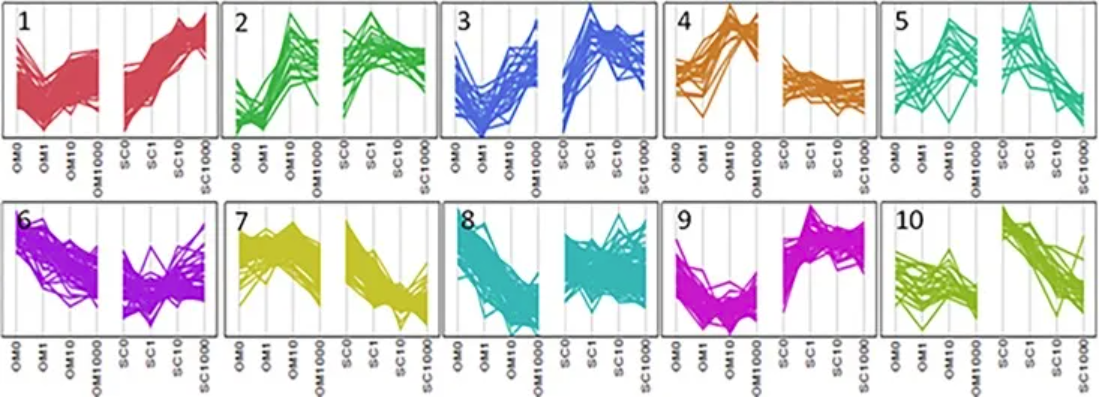
平行图说明了表现出 Depot*[Dex] 相互作用的基因的聚类分析。[3]
参考文献
[1] Frappier V, Najmanovich RJ. A coarse-grained elastic network atom contact model and its use in the simulation of protein dynamics and the prediction of the effect of mutations. PLoS Comput Biol. 2014 Apr 24;10(4):e1003569. doi: 10.1371/journal.pcbi.1003569. PMID: 24762569; PMCID: PMC3998880.
[2] Jia T, Tao H, Qin K, Wang Y, Liu C, Gao Q. Selecting the optimal healthcare centers with a modified P-median model: a visual analytic perspective. Int J Health Geogr. 2014 Oct 22;13:42. doi: 10.1186/1476-072X-13-42. PMID: 25336302; PMCID: PMC4293817.
[3] Pickering RT, Lee MJ, Karastergiou K, Gower A, Fried SK. Depot Dependent Effects of Dexamethasone on Gene Expression in Human Omental and Abdominal Subcutaneous Adipose Tissues from Obese Women. PLoS One. 2016 Dec 22;11(12):e0167337. doi: 10.1371/journal.pone.0167337. PMID: 28005982; PMCID: PMC5179014.
[4] Schloerke, B., Crowley, J., Cook, D., Hofmann, H., Wickham, H. (2021). GGally: Extension to ‘ggplot2’. https://cran.r-project.org/package=GGally
[5] Rudis, B. (2020). hrbrthemes: Additional Themes and Theme Components for ‘ggplot2’. https://cran.r-project.org/package=hrbrthemes
[6] Garnier, S. (2018). viridis: Colorblind-Friendly Color Maps for R. https://cran.r-project.org/package=viridis
[7] Wickham, H., François, R., Henry, L., Müller, K. (2023). dplyr: A Grammar of Data Manipulation. https://cran.r-project.org/package=dplyr
[8] Wickham, H., Henry, L. (2023). tidyr: Tidy Messy Data. https://cran.r-project.org/package=tidyr
[9] Müller, K. (2023). tibble: Simple Data Frames. https://cran.r-project.org/package=tibble
[10] Aumayr, A., & Münch, B. (2022). ggbump: Bump Charts with ggplot2. https://cran.r-project.org/package=ggbump
[11] Neuwirth, E. (2023). RColorBrewer: ColorBrewer Palettes. https://cran.r-project.org/package=RColorBrewer