# Install packages
if (!requireNamespace("data.table", quietly = TRUE)) {
install.packages("data.table")
}
if (!requireNamespace("jsonlite", quietly = TRUE)) {
install.packages("jsonlite")
}
if (!requireNamespace("ggwordcloud", quietly = TRUE)) {
install.packages("ggwordcloud")
}
if (!requireNamespace("curl", quietly = TRUE)) {
install.packages("curl")
}
if (!requireNamespace("png", quietly = TRUE)) {
install.packages("png")
}
# Load packages
library(data.table)
library(jsonlite)
library(ggwordcloud)
library(curl)
library(png)ggwordcloud
Note
Hiplot website
This page is the tutorial for source code version of the Hiplot ggwordcloud plugin. You can also use the Hiplot website to achieve no code ploting. For more information please see the following link:
The word cloud is to visualize the “keywords” that appear frequently in the web text by forming a “keyword cloud layer” or “keyword rendering”.
Setup
System Requirements: Cross-platform (Linux/MacOS/Windows)
Programming language: R
Dependent packages:
data.table;jsonlite;ggwordcloud
sessioninfo::session_info("attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.6.0 (2026-04-24)
os Ubuntu 24.04.4 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate C.UTF-8
ctype C.UTF-8
tz UTC
date 2026-05-09
pandoc 3.1.3 @ /usr/bin/ (via rmarkdown)
quarto 1.9.37 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
curl * 7.1.0 2026-04-22 [1] RSPM
data.table * 1.18.4 2026-05-06 [1] RSPM
ggplot2 * 4.0.3.9000 2026-05-04 [1] Github (tidyverse/ggplot2@6870419)
ggwordcloud * 0.6.2 2024-05-30 [1] RSPM
jsonlite * 2.0.0 2025-03-27 [1] RSPM
png * 0.1-9 2026-03-15 [1] RSPM
[1] /home/runner/work/_temp/Library
[2] /opt/R/4.6.0/lib/R/site-library
[3] /opt/R/4.6.0/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────Data Preparation
Load data nouns and noun frequencies.
# Load data
data <- data.table::fread(jsonlite::read_json("https://hiplot.cn/ui/basic/ggwordcloud/data.json")$exampleData$textarea[[1]])
data <- as.data.frame(data)
inmask <- "https://download.hiplot.cn/api/file/fetch/?path=public/demo/ggwordcloud/hearth.png"
# Convert data structure
col <- data[, 2]
data <- cbind(data, col)
# View data
head(data) word freq col
1 oil 85 85
2 said 73 73
3 prices 48 48
4 opec 42 42
5 mln 31 31
6 the 26 26Visualization
# ggwordcloud
p <- ggplot(data, aes(label = word, size = freq, color = col)) +
scale_size_area(max_size = 40) +
theme_minimal() +
geom_text_wordcloud_area(
mask = png::readPNG(curl::curl_fetch_memory(inmask)$content),
rm_outside = TRUE) +
scale_color_gradient(low = "#8B0000", high = "#FF0000")
p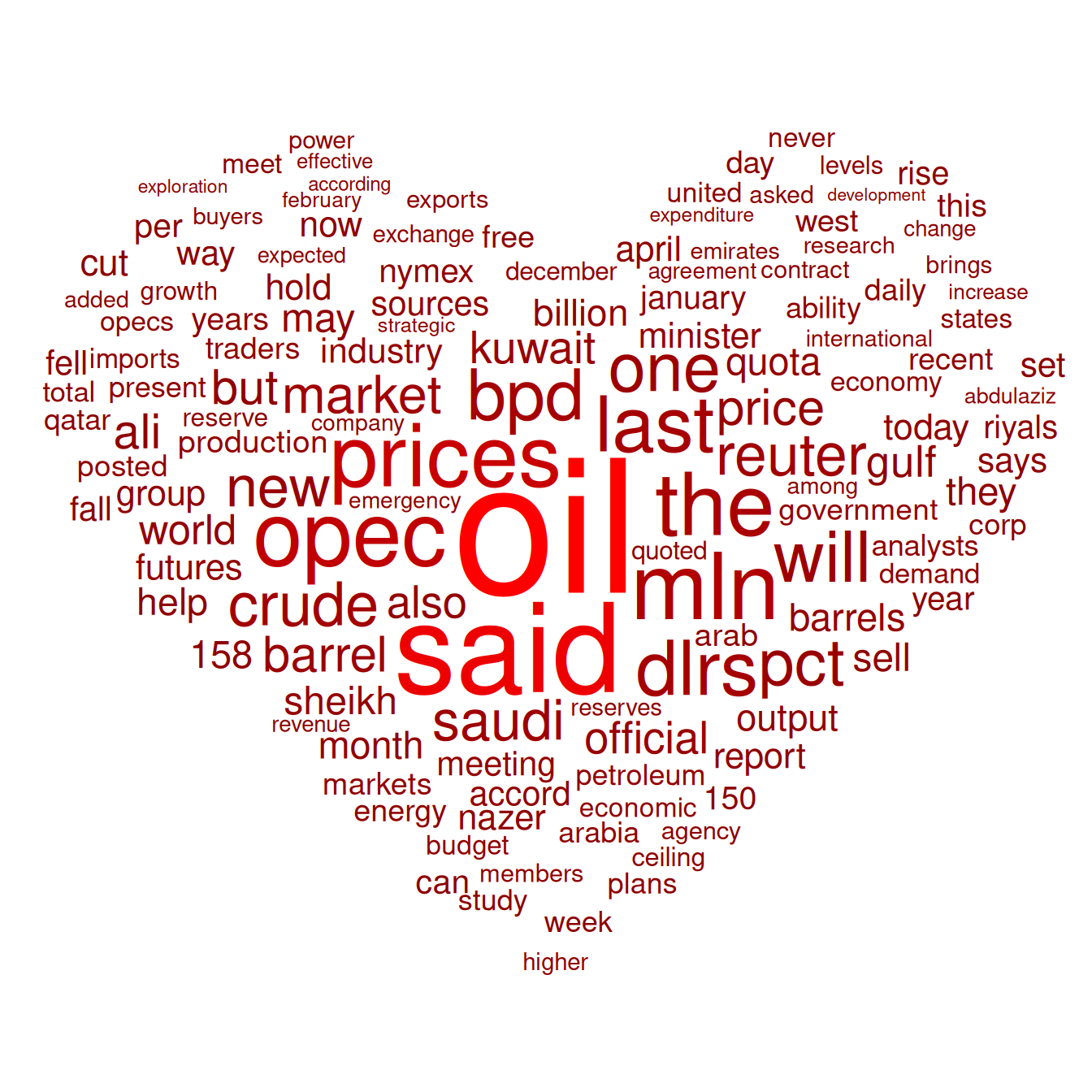
Display the proportion of nouns in the word cloud graph according to the frequency of nouns.