生信爱好者周刊(第 65 期):125个科学问题:探索与发现¶
这里记录每周值得分享的生信相关内容,周日发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。
封面图¶

本周话题:125个科学问题:探索与发现¶
2005年,在庆祝创刊125周年之际,Science公布了125个最具挑战性的科学问题。对指引近十几年的科学发展产生积极影响,详见: Science公布:全世界最前沿的125个科学问题。 16年之后的2021年,随着科学的不断突破,许多问题得到一定程度的解答,一些问题也更加深入。近日,上海交通大学携手Science杂志发布了“新125个科学问题”——《125个科学问题:探索与发现》。
@JnanZhang:“每一项科学突破都始于一个问题。我们可能无法立即提供所有答案,但也许共享问题并与他人进行对话,是一个很好的起点。”
生信研究¶
1、 Nucleic Acids Research | 汤富酬课题组实现基于单细胞测序数据的人类基因组从头组装
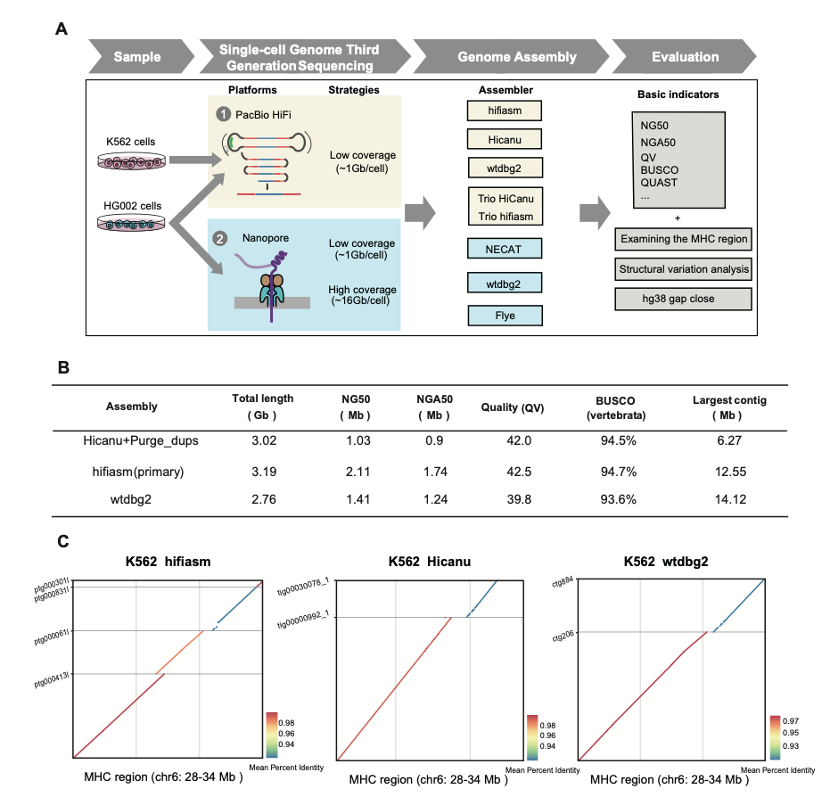
汤富酬课题组使用单细胞基因组三代测序技术,首次在单细胞水平上完成了 Mb 级连续性的人类基因组组装。此技术可以用来解决人类基因组从头组装在实际应用中遇到的细胞遗传异质性和细胞稀缺性的问题。通过该方法,作者能够在单细胞水平(少至30个单细胞)实现高质量基因组组装,并确定了影响组装结果的主要因素。研究结果表明,使用单细胞测序数据从头组装人类基因组是可行的,并且该方法具有较高的分辨率,可以更准确地解析单个细胞的基因组特征。这一技术的成功开发将为单细胞基因组研究和人类基因组的从头组装提供更有效的工具和方法。
- 论文链接:https://academic.oup.com/nar/article/50/13/7479/6640236
2、The Innovation | 用系统生物学的观点鸟瞰肿瘤易感基因
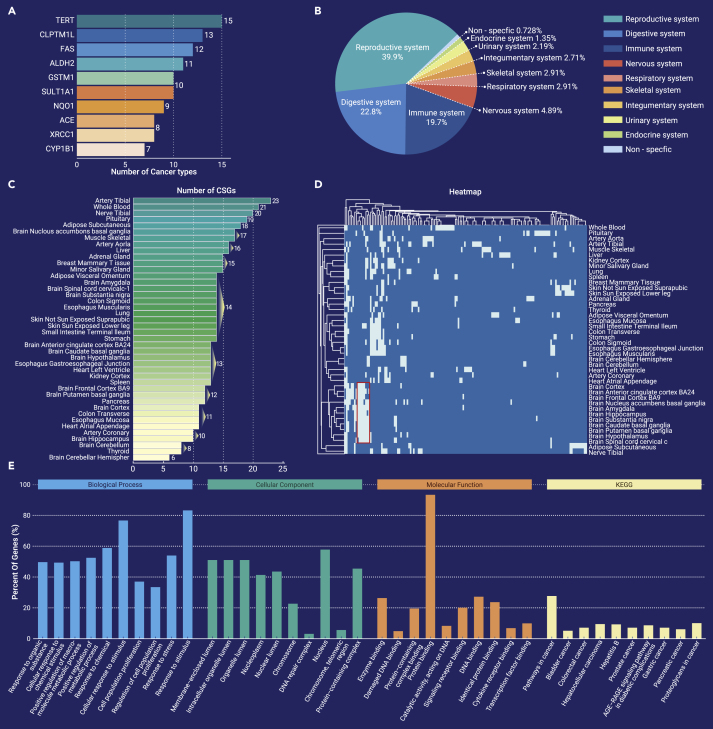
癌症易感基因(Cancer susceptibility gene)是一类可引起癌症发生风险增加的基因。这些基因的突变可能导致细胞发生异常增殖和恶性转化。因此,通过检测一个人的癌症易感基因概况,可以评估其癌症风险,并为个性化癌症预防和治疗提供启示。这篇文章里来自西澳大利亚大学的 Grant Morahan 教授团队整理了目前最新的肿瘤易感基因列表,并对其进行了系统性的分析。该研究对癌症易感基因的功能、调节机制以及与不同类型癌症的相关性进行了深入研究。研究结果表明,这些肿瘤易感基因在不同类型的癌症中具有不同的作用和表达模式。此外,研究团队还发现一些新的与癌症相关的基因,并提供了新的理解癌症发生和发展机制的线索。这项研究的发现有望为个性化的癌症预防提供新的契机,为基于肿瘤易感基因的治疗策略提供更为精准的指导,有望推动癌症研究和治疗的进一步发展。
- 论文链接:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9294327/
3、 Mol Cell | 绘制人类RNA翻译的高分辨率图谱
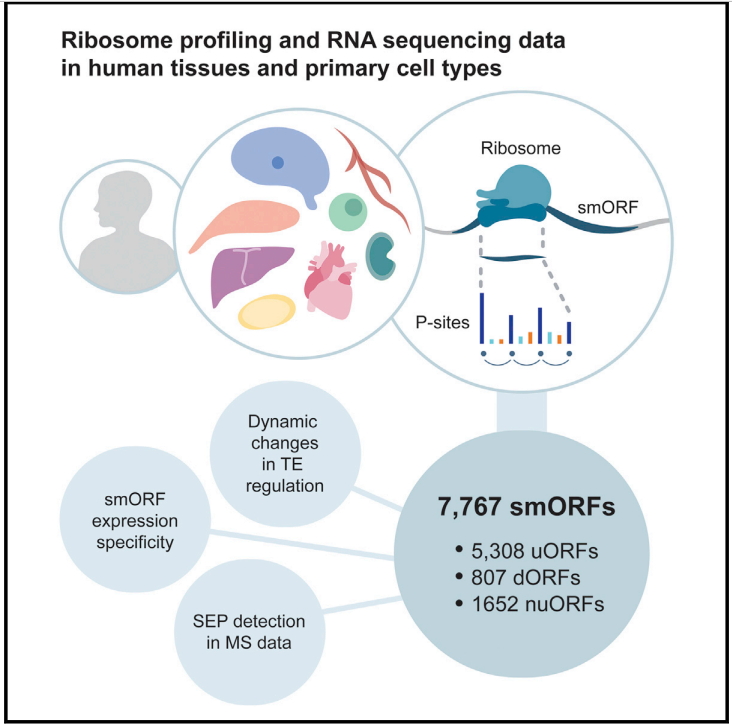 新加坡杜克-新加坡国立大学的Sebastian Schafer和Owen J.L. Rackham课题组确定了六种主要人类细胞类型和五种组织的核糖体位置,并检测到7767个具有与已知蛋白质匹配的翻译谱的smORFs。发现人类基因组包含高度特异性的细胞类型和组织smORFs,并且它的很大的一部分能够编码高度保守的氨基酸序列。这些研究与456个质谱数据集一起证实了人类蛋白水平上存在603个小肽,并为这些小蛋白的亚细胞定位提供了见解。本研究提供了一个来自原代人类细胞和组织的高置信度翻译的smORFs的全面图谱,帮助我们对翻译的人类基因组提供更全面的理解。
- 论文链接:https://doi.org/10.1016/j.molcel.2022.06.023
新加坡杜克-新加坡国立大学的Sebastian Schafer和Owen J.L. Rackham课题组确定了六种主要人类细胞类型和五种组织的核糖体位置,并检测到7767个具有与已知蛋白质匹配的翻译谱的smORFs。发现人类基因组包含高度特异性的细胞类型和组织smORFs,并且它的很大的一部分能够编码高度保守的氨基酸序列。这些研究与456个质谱数据集一起证实了人类蛋白水平上存在603个小肽,并为这些小蛋白的亚细胞定位提供了见解。本研究提供了一个来自原代人类细胞和组织的高置信度翻译的smORFs的全面图谱,帮助我们对翻译的人类基因组提供更全面的理解。
- 论文链接:https://doi.org/10.1016/j.molcel.2022.06.023
4、BMC Bioinformatics | 联合深度学习优化代谢组学研究
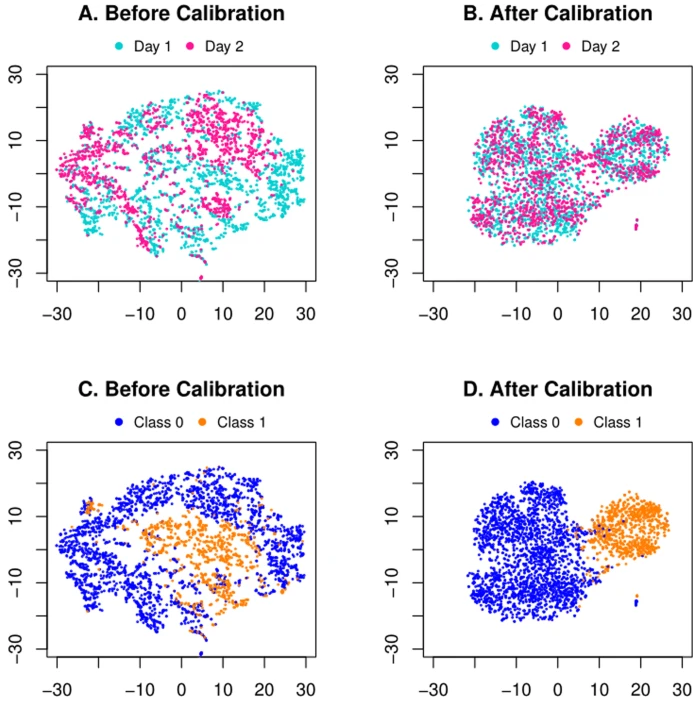
代谢组学是一个主要的组学课题,在代谢特征和生物标志物的临床应用和基础研究中都占有重要地位。不幸的是,相关研究受到许多外部因素造成的批次效应的挑战。在过去十年中,深度学习技术已成为数据科学中的主要工具,人们可以从已知批次训练诊断网络,然后将其推广到新批次。然而,批次效应不可避免地阻碍了这种努力,因为所考虑的两个批次可能高度不匹配。上海交通大学和上海科技大学的研究人员提出了一个端到端的深度学习框架,用于联合批次效应去除,然后对代谢组学数据进行分类。
- 论文链接:https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-022-04758-z
博文资讯¶
5、 https://www.rstudio.com/blog/shiny-and-arrow/
shiny是一个令人难以置信的工具,它将数据科学带入日常生活。同时,它可以帮助将分析结果传达给非技术利益相关人员,或为任何人提供自助式的数据探索。本文介绍了Ketchbrook Analytics首席数据科学家Michael Thomas如何利用shiny有效利用数据帮助企业获得显著的竞争优势。

本推文分享了笔者从文献阅读前、阅读中、阅读后这三个过程中的心得体会,并介绍了各阶段的相关工具。
7、 NEJM | 神速!基于纳米孔测序的产前检测方法可2小时内快速鉴定胎儿染色体异常
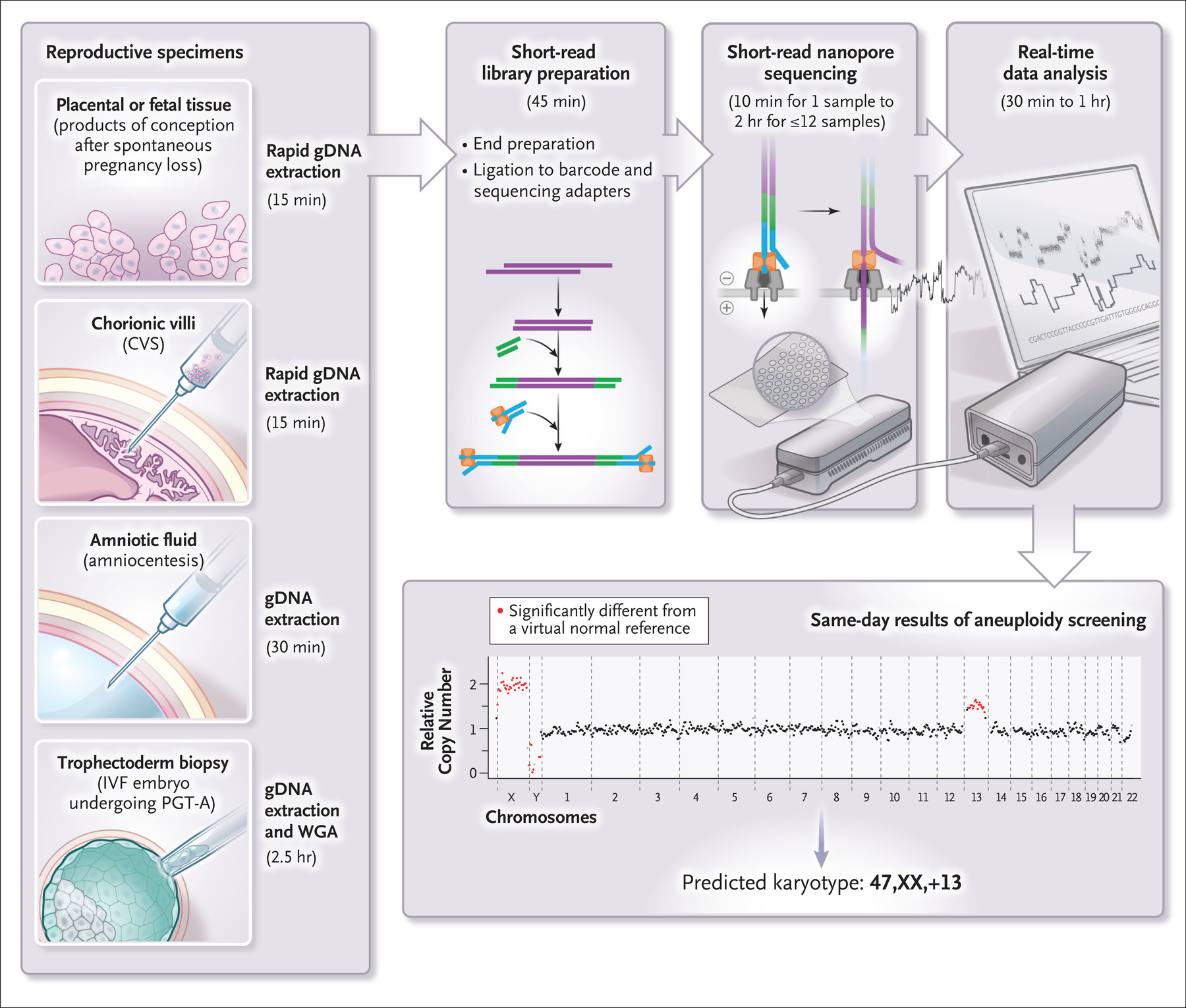 研究团队基于纳米孔测序技术开发了可分析DNA微小片段的STORK方法,可在2小时内提供结果,比目前可用的染色体检测方法快15,000倍,且每个样本的处理成本约为当前检测的十分之一。此外,STORK方法只需使用约有口琴大小的测序设备,重量仅为 450克,在医生办公室内即可完成检测。
- 论文链接:https://www.nejm.org/doi/10.1056/NEJMc2201810
研究团队基于纳米孔测序技术开发了可分析DNA微小片段的STORK方法,可在2小时内提供结果,比目前可用的染色体检测方法快15,000倍,且每个样本的处理成本约为当前检测的十分之一。此外,STORK方法只需使用约有口琴大小的测序设备,重量仅为 450克,在医生办公室内即可完成检测。
- 论文链接:https://www.nejm.org/doi/10.1056/NEJMc2201810
 本文主要是对常用的各类 LaTeX 符号进行汇总,方便大家查询。主要参考 CSDN 文章 和 AoPS Wiki 网站。
本文主要是对常用的各类 LaTeX 符号进行汇总,方便大家查询。主要参考 CSDN 文章 和 AoPS Wiki 网站。
工具¶
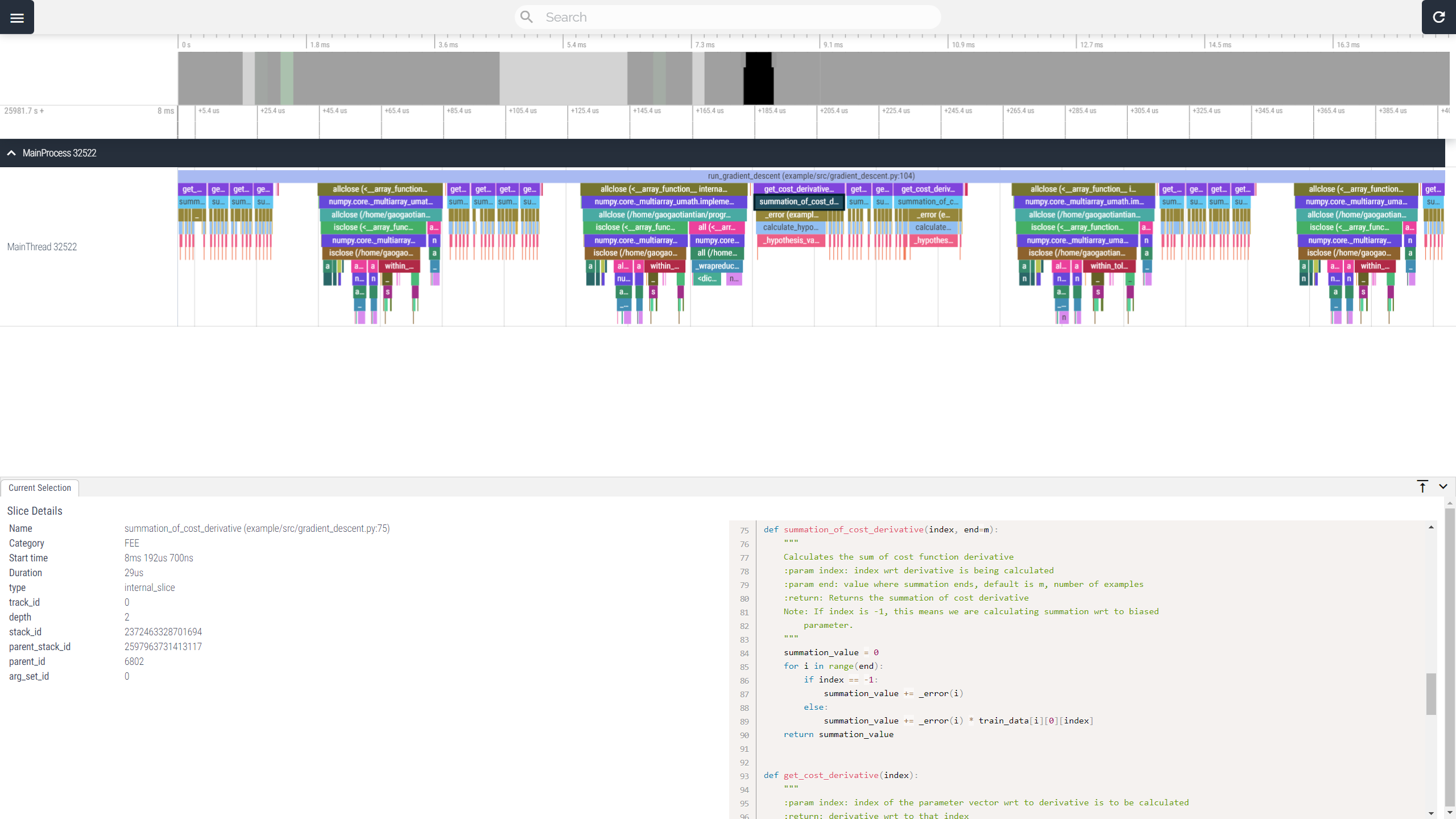
VizTracer 是一款用于 Python 代码的调试和性能分析的工具,可追踪和可视化 Python 代码的执行过程。它易于使用,支持多线程,并且适用于 Linux、MacOS 和 Windows 等多个操作系统。
- 工具链接:https://github.com/gaogaotiantian/viztracer
10、Mito-一款超级棒的 JupyterLab 扩展程序
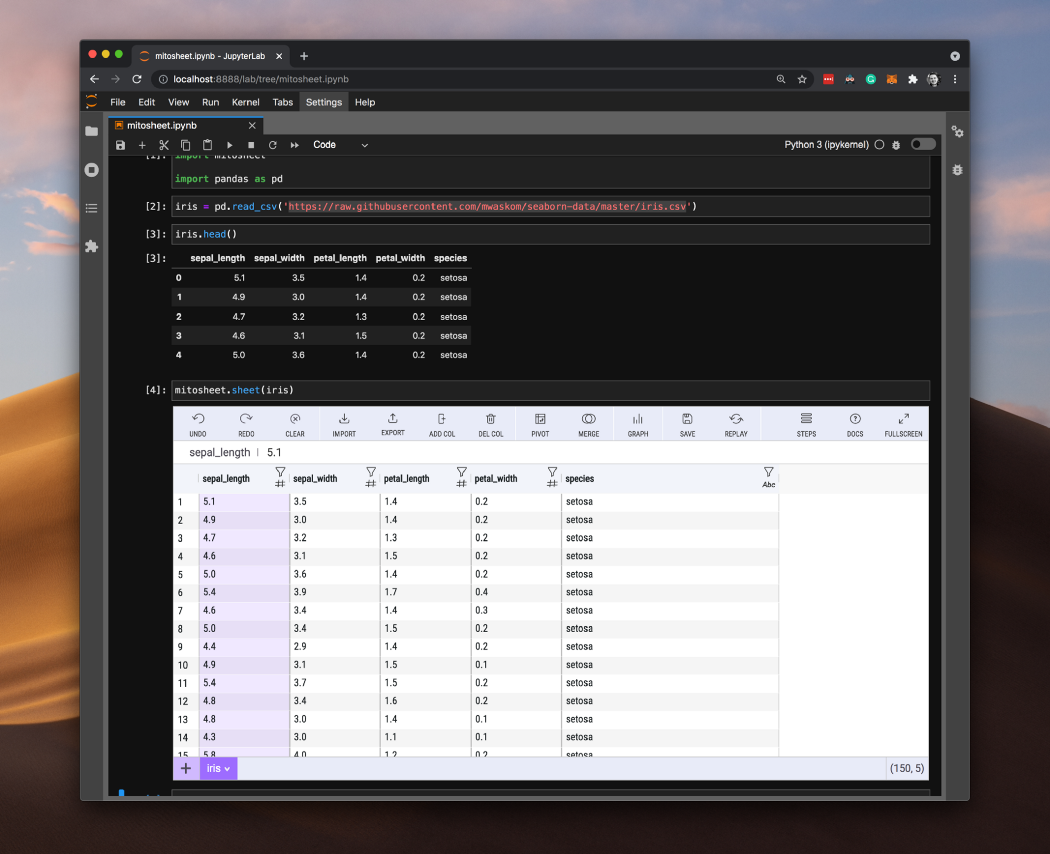
Mito 是一个免费的 JupyterLab 扩展程序,可以使用 Excel 轻松探索和转换数据集。
11、代谢物溯源/微生物组与代谢组整合分析软件MetOrigin
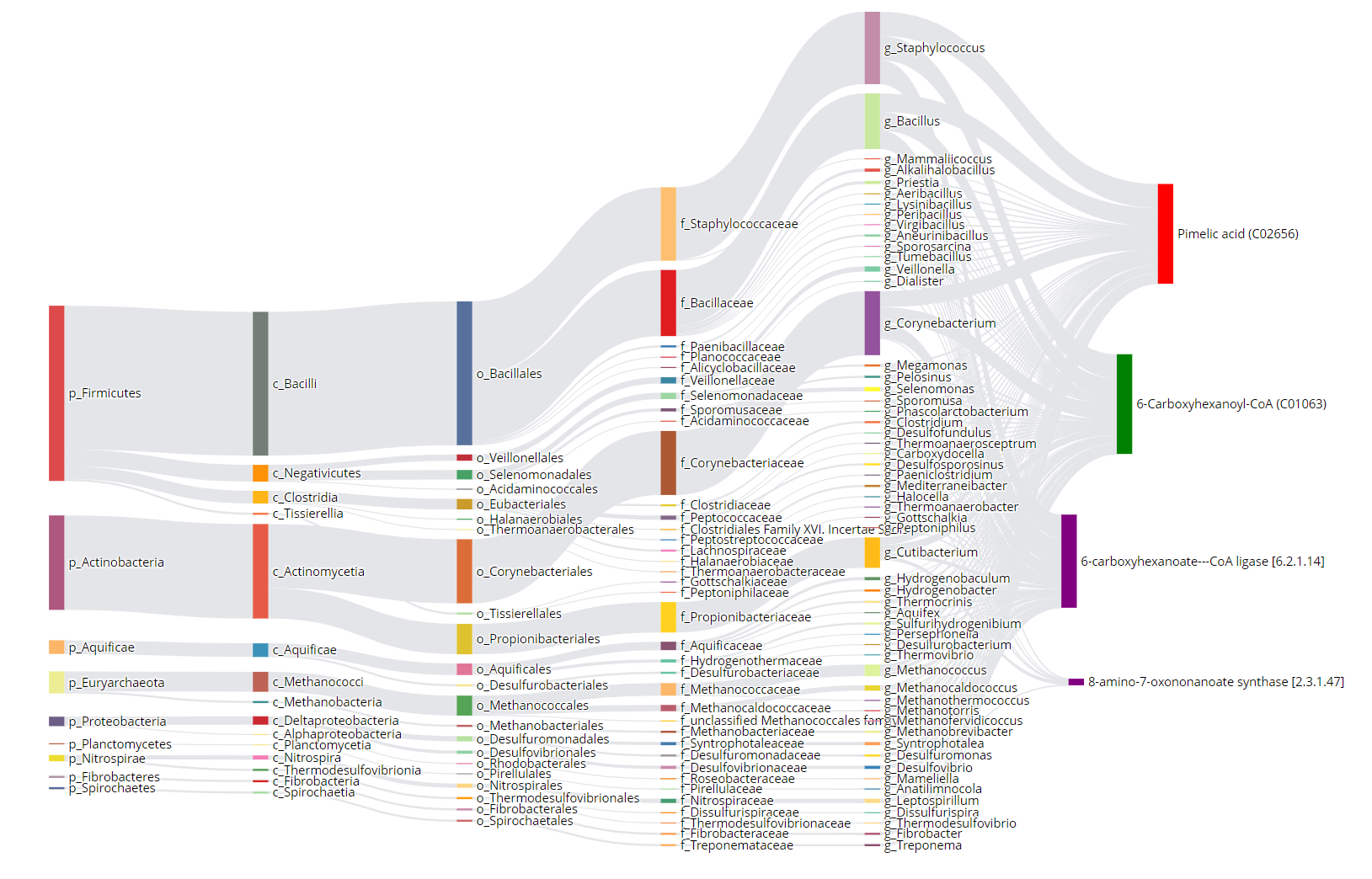
肠道微生物组和代谢组之间的相互作用在人类健康和疾病中起重要作用。当前的研究主要采用肠道微生物组和所有确定的代谢物之间的统计相关分析来探索其关系。然而,在没有体外培养实验的情况下,确定微生物的特定代谢功能仍然具有挑战性。区分微生物代谢物与其他人(例如宿主,食物或环境)并探索其代谢功能以及与微生物组的相关性可能会提高生物标志物发现的效率和准确性。到目前为止还没有此类生物信息学工具可用。本文开发了Metorigin交互式Web服务器,可区分源自微生物组的代谢物,执行基于原始的代谢途径富集分析,并使用Sankey网络可视化在数据库中集成了数据库中的统计相关性和生物关系。 Metorigin不仅可以快速鉴定微生物代谢物及其代谢功能,而且还促进了发现特定细菌物种,这些细菌物种在统计和生物学上与代谢物紧密相关。
资源¶
12、SoupX-检测并清除单细胞测序中的外源性mRNA的R包
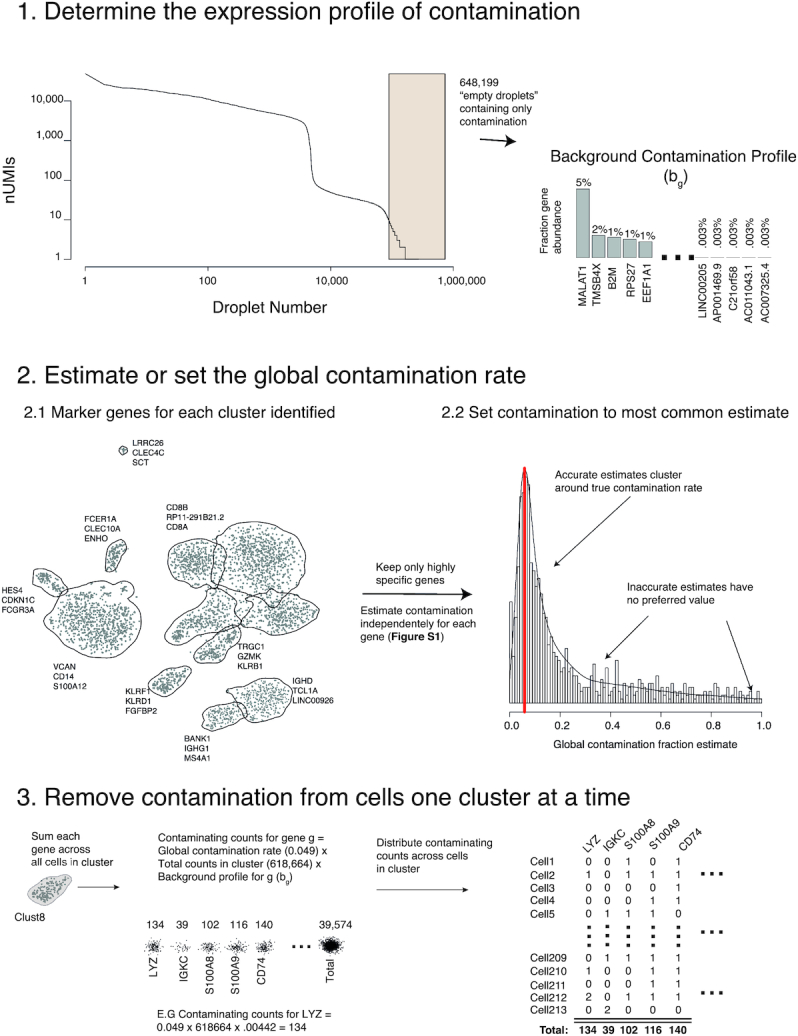
- 文献链接:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7763177/
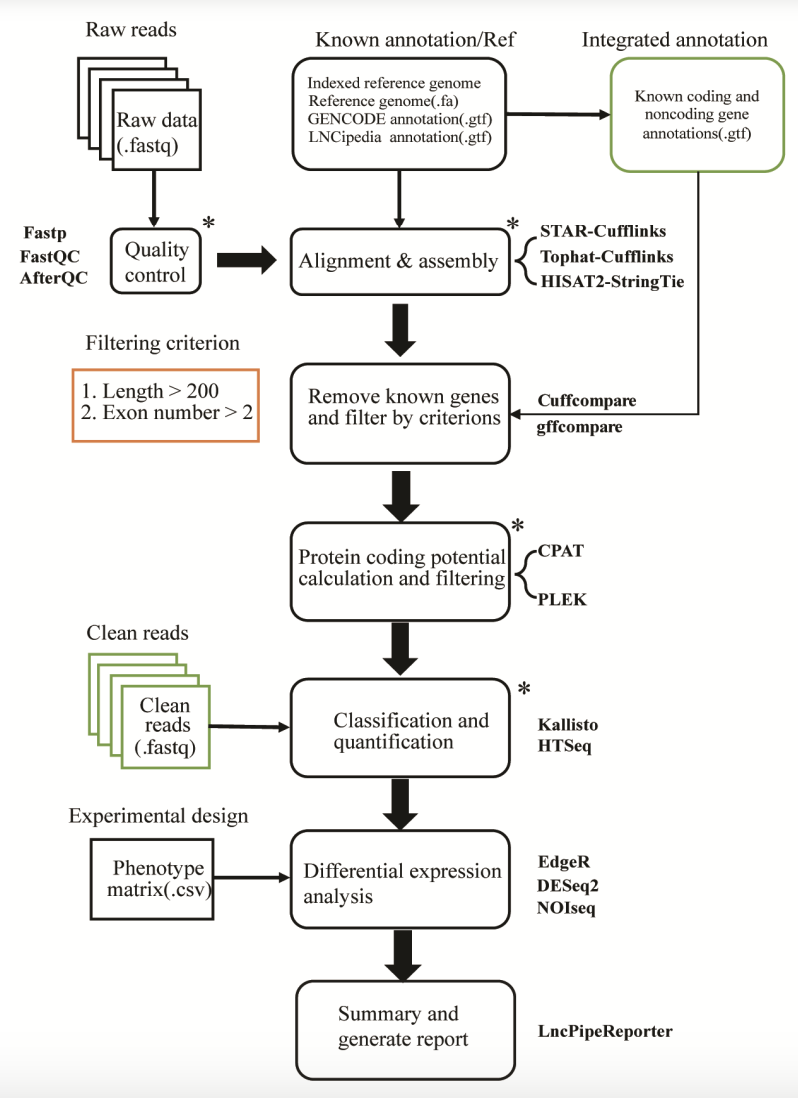
13、LncPipe | 一个基于nextflow的管道,用于从RNA-seq数据集中全面分析长非编码RNA
14、https://github.com/shiftkey/desktop
GitHub Desktop是一个基于Electron的开源GitHub app。此存储库包含上游存储库顶部的特定补丁,以支持 Linux 的使用。同时,它还托管各种 Linux 发行版的预览包。
- 链接:https://github.com/shiftkey/desktop
历史上的本周¶
- 第25期:从事生信工作,究竟是远见者,还是工具人?
贡献者(GitHub ID)¶
「Openbiox 生信周刊」运维小队:
@ShixiangWang(王诗翔)@kkjtmac(阚科佳)@NiEntropy(赵启祥)@He-Kai-fly(何凯)@JnanZhang(张佳楠)@Tomcxf(陈啸枫)@wangdepin(王德品)@kongjianyang(空间阳)
订阅¶
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。

(完)