生信爱好者周刊(第 35 期):生物信息行业的经济生态¶
公告:从本期开始,本周刊将由Openbiox近期建立的运维小队共同贡献与管理。
这里记录每周值得分享的生信相关内容,周日发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。
封面图¶
神经元(via)
本周话题:生物信息行业的经济生态¶
本周话题来自@qins:
任何一个领域或行业要蓬勃发展, 大概率会有需求方(资金来源) -> 整合链接方(分发网络) -> 提供方(实现者), 很多时候链条会重复。明确和公开了各方角色, 行业就相当于进入市场经济, 而市场经济更容易规范和刺激领域或行业发展。另外, 生信人也是要恰饭的, 如果搞生信能轻松养家糊口, 相信也会有更多人参与进来。
对于这个话题,对于学术界的你或者工业界的你有什么感想和看法?
@ShixiangWang - 个人感觉生信在工业界存在着两极分化,一类生信工作为测序和原始数据的处理,这类稳定且易被管道化,已经变成了当前生物医学的核心基础服务之一,由于变成了基础服务,从业者往往不被探索学术PI们所注意;第二类生信工作是公司与学术PI们的个性化服务或合作,由于研究的复杂性和不确定性,很难有pipeline的建立,说到底工业界盈利依赖的稳定量产与学术界的个性创新从根本上是冲突的,从业者很难提供相应的可靠服务,帮客户发文章的同时,又展现自身的“钱途”。这也是为什么在基础研究实验室,现在学术PI们喜欢专门招一两个学术去从事生信工作。
生信研究¶
1、Nature | 深度学习神经网络模型「神谕」预测非编码DNA序列的突变会如何影响基因表达
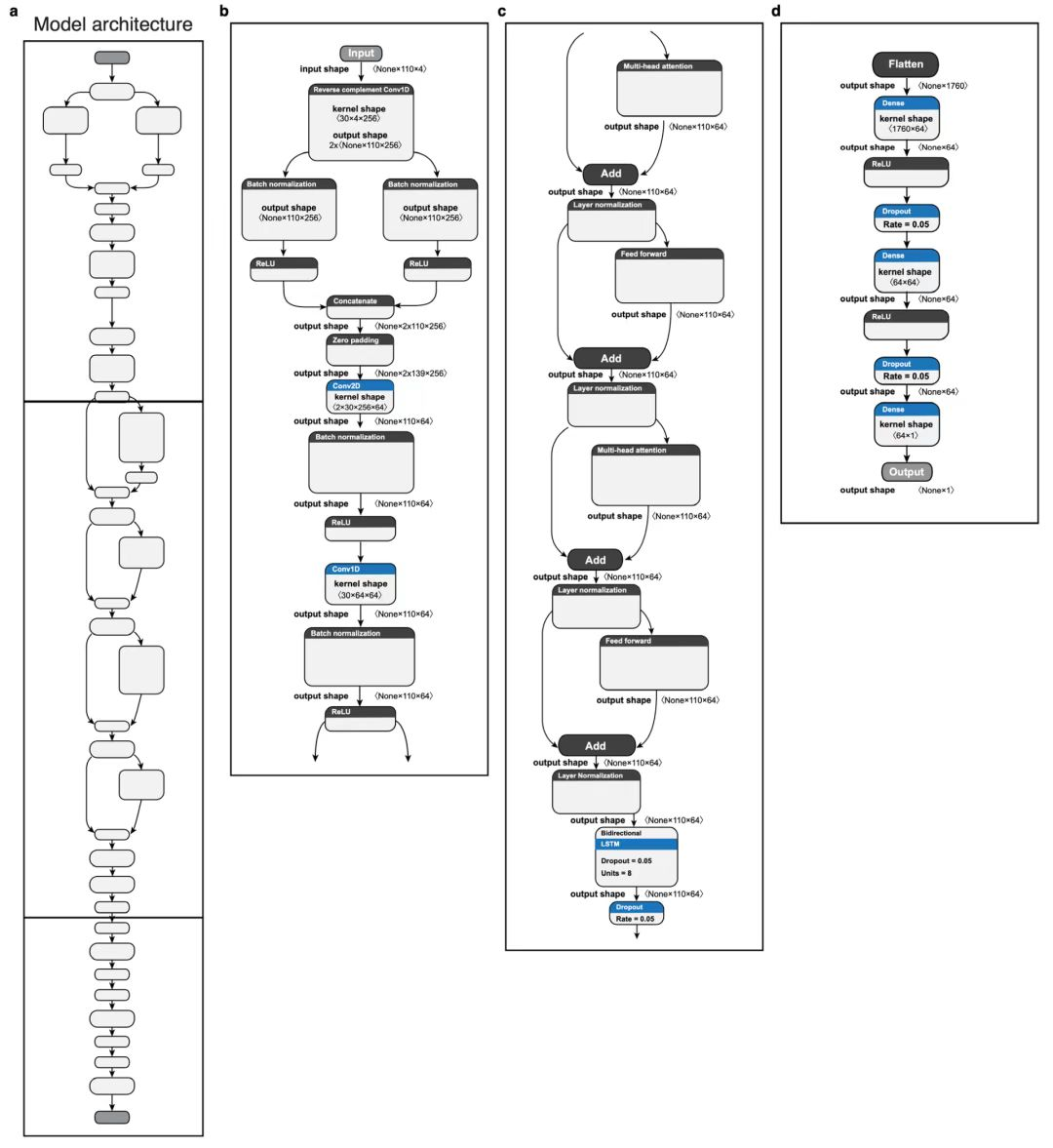
来自麻省理工学院和英属哥伦比亚大学等机构的研究人员构建了一个深度学习神经网络模型“神谕”。在利用数亿次实验观测结果进行训练之后,「神谕」可以预测酵母中的非编码DNA序列的突变会如何影响基因表达。这个无偏模型能够基于任何可能的DNA序列,来预测生物体的适应性和基因表达。
2、Nature Genetics | 哺乳动物胚胎发生细胞轨迹的系统重建
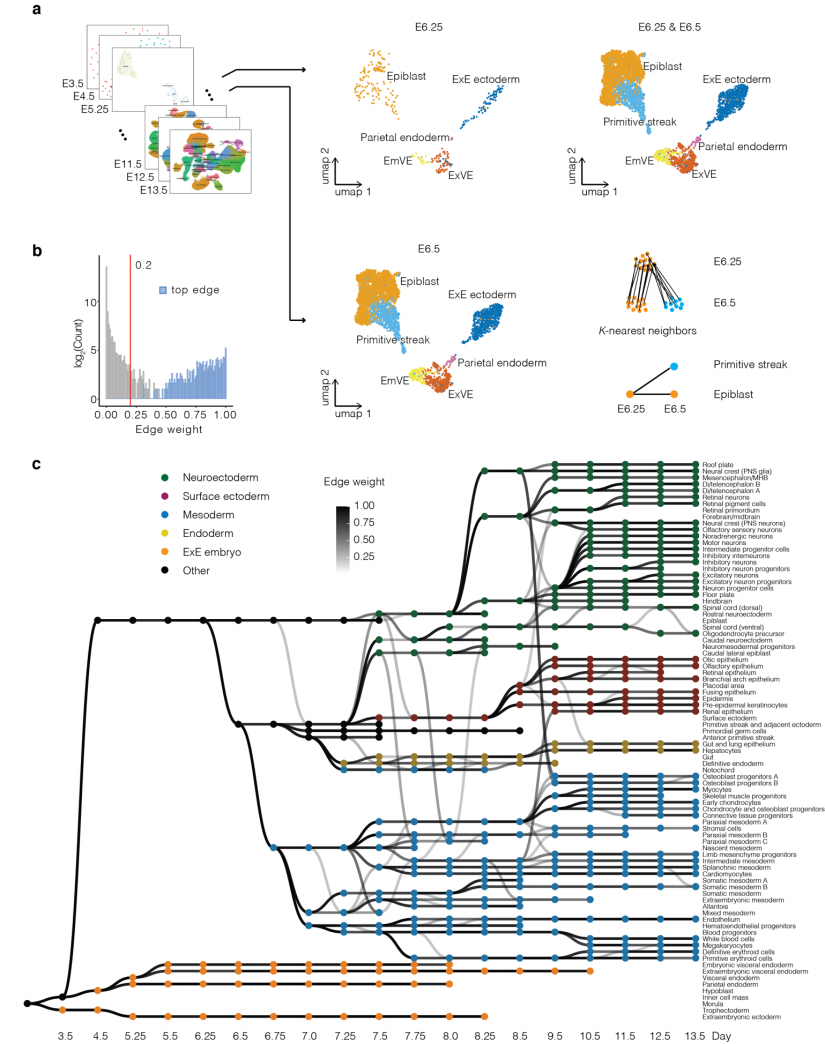
在本研究中,研究者着手整合几个与小鼠原肠胚形成和器官形成相关的单细胞RNA序列数据集。此外,作者定义了跨越E3.5到E13的19个连续阶段中每个阶段的细胞状态,试探性地将它们与其伪祖先和伪后代联系起来。尽管是通过自动化程序构建的,但由此产生的哺乳动物胚胎发生轨迹(TOME)在很大程度上与我们当代对哺乳动物发育的理解一致。作者还利用TOME指定转录因子(TF)和TF基序作为新细胞类型出现的每个分支点的关键调节因子。最后,为了便于脊椎动物之间的比较,作者对斑马鱼和青蛙胚胎发育相关的单细胞数据集应用相同的程序,并根据共享的调节器和转录状态指定“细胞类型同源物”。
3、bioRxiv | 949种人类细胞蛋白质组学检测与多组学分析
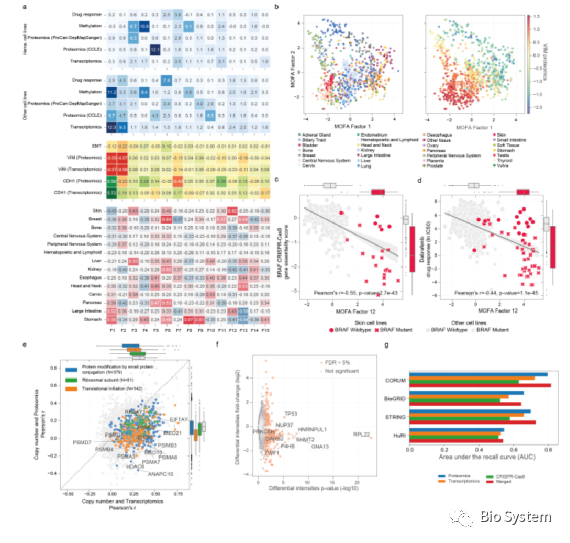
本研究报道在949种人类细胞中进行的蛋白质组学分析,并与之前的一些大规模组学数据整合,形成了Cell Model Passports数据库:https://cellmodelpassports.sanger.ac.uk/ 。主要研究成果包括: - (1)蛋白质组数据与细胞类型分析; - (2)MOFA多组学分析; - (3)DeeProM深度学习分析肿瘤潜在脆弱性(vulnerabilities)靶点。
4、Cancer Cell | 动态单细胞数据探索三阴性乳腺癌在化疗或化疗联合免疫治疗过程中关键免疫细胞亚群的演化
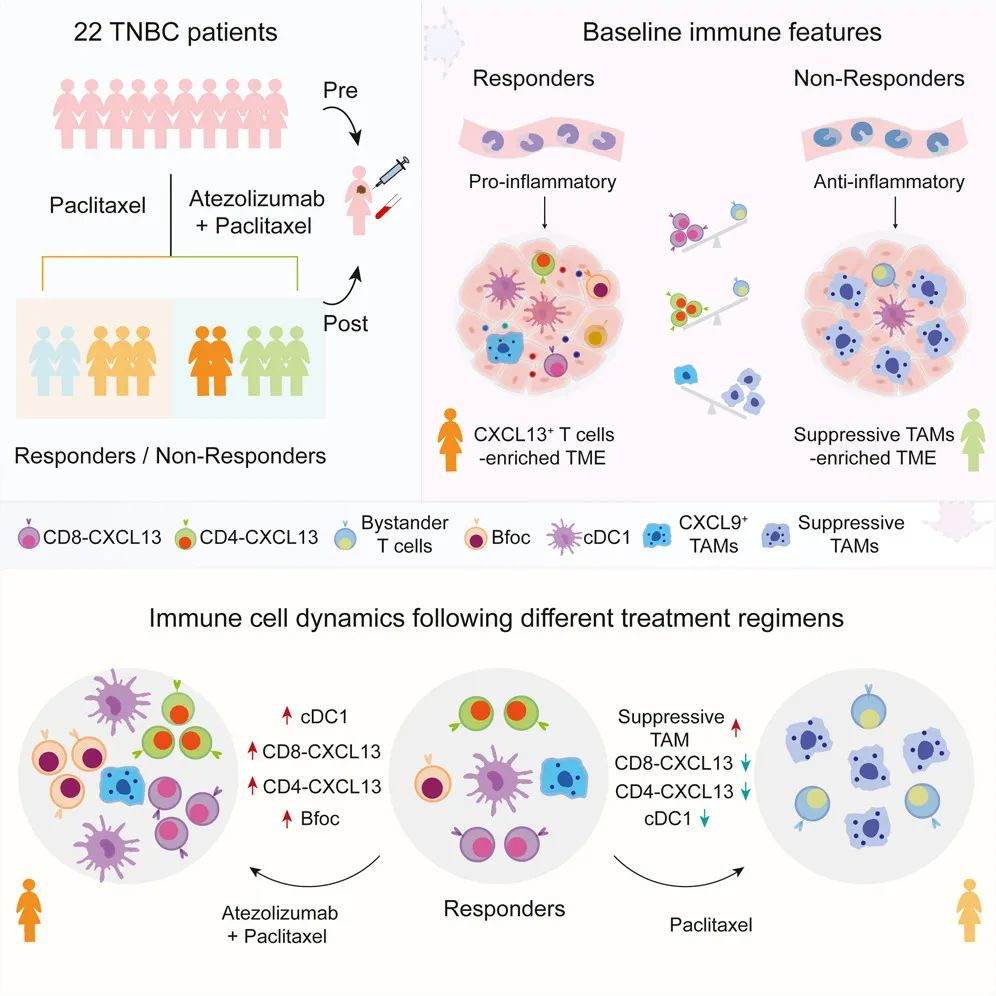
在三阴性乳腺癌 (TNBC) 中,联合化疗与检查点抑制剂的益处仍不是很清楚。本文利用单细胞 RNA 和 ATAC 测序来检查 22 名接受紫杉醇或其与PD-L1抑制剂阿替利珠单抗联合治疗的晚期 TNBC 患者的免疫细胞动态变化。证明了高水平的基线 CXCL13+ T 细胞与巨噬细胞的促炎特征有关,并且可以预测对联合治疗的有效反应。在有反应的患者中,淋巴组织诱导细胞 (LTi) 、滤泡B细胞 (Bfoc) 、CXCL13+ T 细胞和经典 1 型树突状细胞 (cDC1) 在联合治疗后协同增加,但在紫杉醇单药治疗后反而减少。该数据强调了 CXCL13+ T 细胞在对PD-L1抑制剂疗法的有效反应中的重要性,并表明紫杉醇方案减少CXCL13+ T细胞可能会不利于阿替利珠单抗治疗 TNBC 的临床结果。
博文资讯¶
5、Android 13虚拟化支持运行Windows 11和桌面版Linux

在2月份,谷歌发布了Android 13 的第一个开发者预览版,而一位名叫kdrag0n的开发者发现了安装该版本的 Google Pixel 6可以虚拟化运行Windows 11和多个版本Linux。随着手机硬件性能的不断提升,加上各平台系统的互通,以后在手机上跑个轻量级生信运算也不是不可能。

机器学习中数据不平衡的分类问题很常见,极端的数据不平衡通常会影响模型预测的准确性和泛化性能。 本文介绍几种处理不平衡数据的计算方法:
- Oversample and downsample
- Generating synthetic data
- GAN
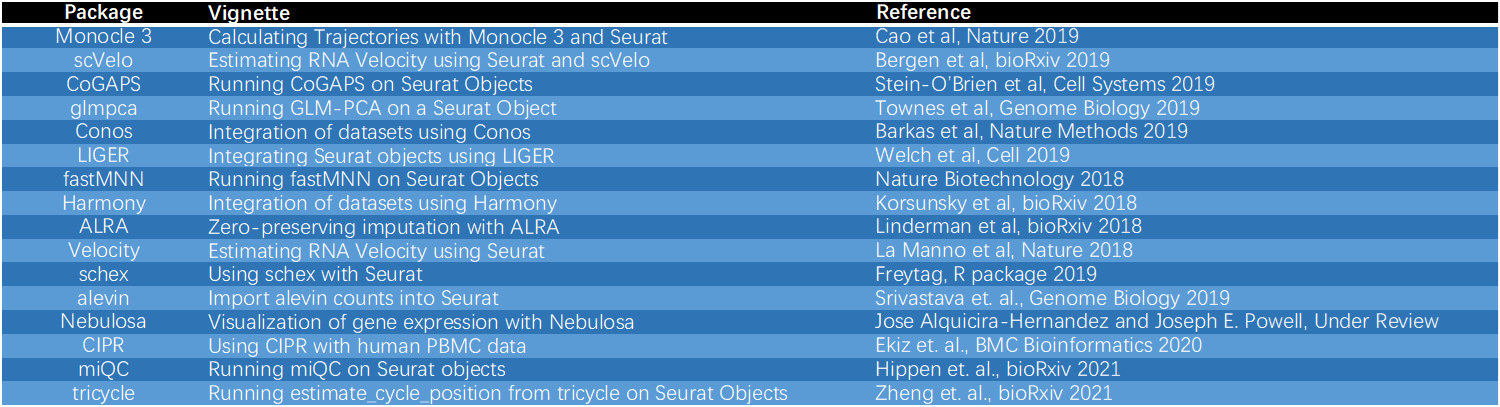
单细胞数据处理的其他分析工具,比如拟时序,细胞通讯和转录因子分析,还有RNA速率等。其结果都可以结合到Seurat的降维聚类分群中做可视化。
比如:生信技能树的笔记——pyscenic的转录因子分析结果展示之5种可视化
Seurat团队开发整理好的包——SeuratWrappers包

平时我们在服务器运维工作中,安装软件时候会出现进度条来提示我们下载的进度,本文通过C语言来简单实现这个功能。
注意:
- 换行是换到下一行当前位置,用\n表示,回车是回到当前行的开始用\r开始,而在C语言中,\n代表换行+回到开始。
- 代码printf执行后,要打印的内容放入缓冲区,但不一定会立即刷新到屏幕上,需注意无缓冲、行缓冲及全缓冲的3种策略
- 每次打印完都回车,就相当于在第一个位置打印一个数字后,又回到该位置,继续打印下一个数字。这样就可以实现倒计时的效果。
工具¶
9、scPred - accurate supervised method for cell-type classification from single-cell RNA-seq data

scPred是一种基于基因表达的低维表示(如PCA)对细胞进行分类的通用方法。
10、scRepertoire:A toolkit for single-cell immune profiling
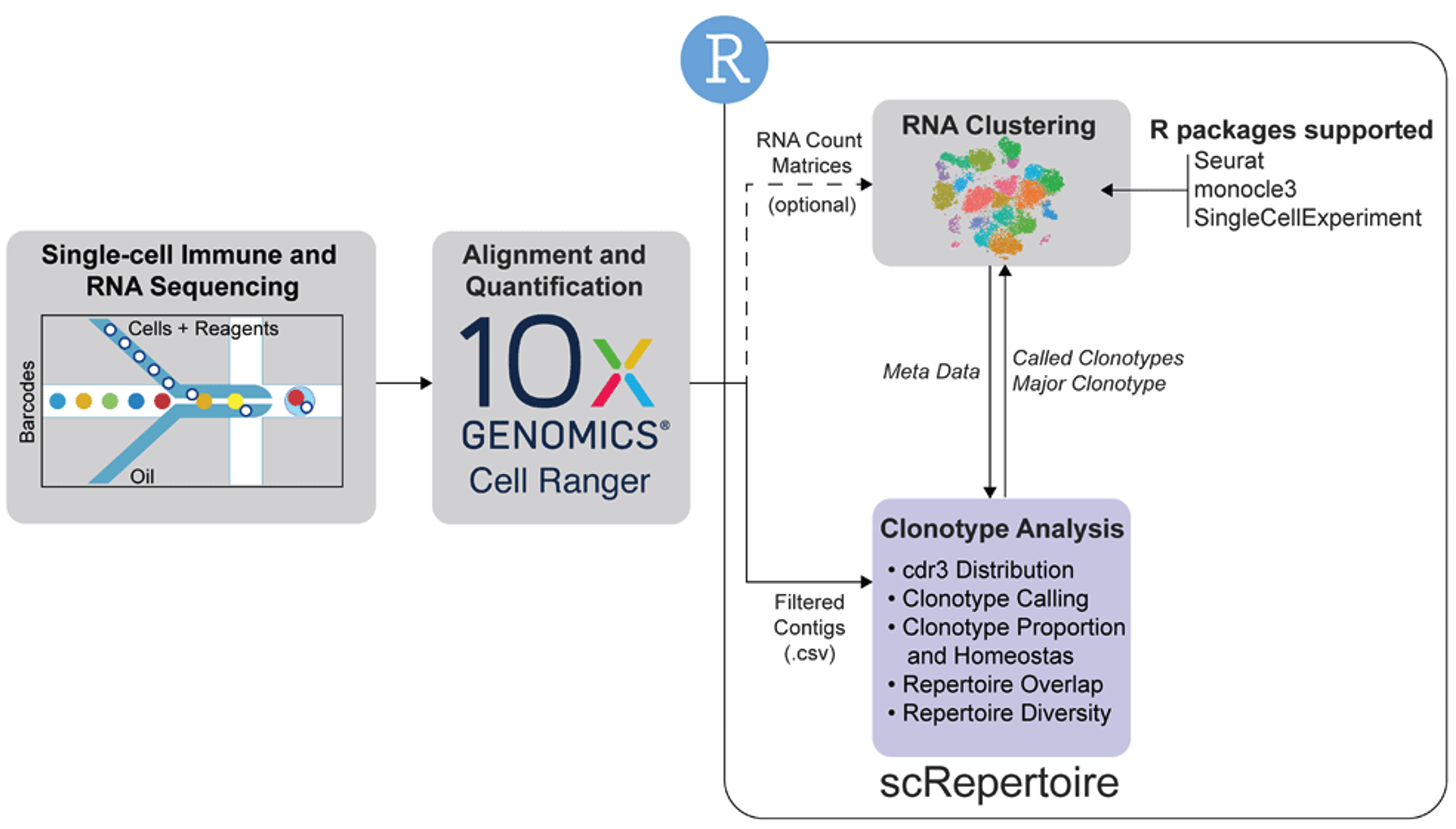
与转录组学领域不同,目前缺乏用于单细胞免疫受体分析的软件选择。为了使用户能够轻松地结合RNA和免疫分析,我们构建了scRepertoire来处理来自t细胞受体(TCR)和免疫球蛋白(Ig)富集工作流程的10x基因组铬免疫分析数据,并随后与流行的Seurat R包相互作用。
11、miniTorch

MiniTorch 是一个为那些希望了解机器学习底层系统内部概念工程师打造的DIY教学库。 它是利用纯Python代码重构的Torch API,其设计简单、易于阅读、测试和增量,最终的库可以运行Torch代码。 该项目是为康奈尔理工大学的机器学习工程课程开发的。
12、lapce
Lapce是一种基于pure Rust的代码编辑器,更加智能化,更加快速。
13、https://jupyterbook.org/intro.html

Jupyter book主要是使用计算机语言来创建发表级别的书籍或文档。
该教程主要分为以下几个主要部分:
- TUTORIALS部分是Jupyter Book的逐步入门指南。
- Topic Guides部分涵盖了更深入的特定区域,并将其组织为离散的“操作方法”部分。
- Reference详细地描述了Jupyter书的API/语法/等。
资源¶

GENIE 汇总了19 个机构的肿瘤患者测序数据,主要是基因组测序数据,如基因突变,拷贝数。
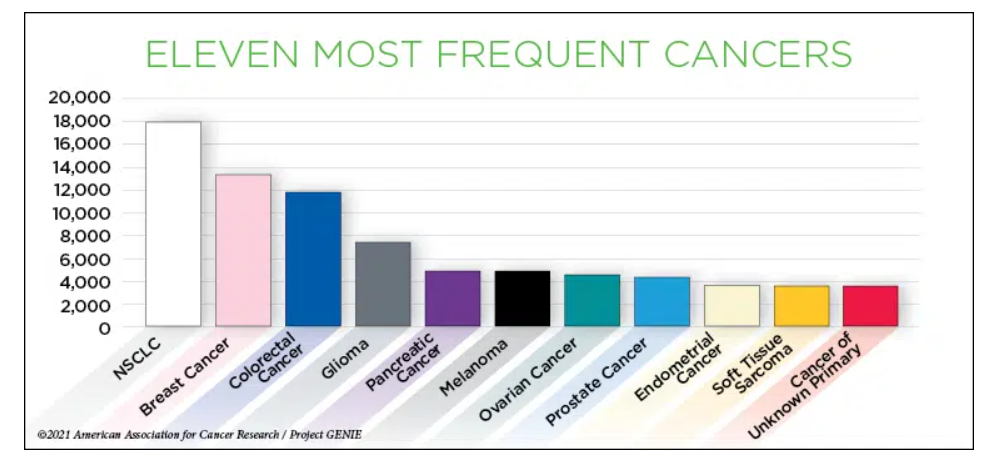
当前的版本 GENIE 11.0-public 于 2022 年 1 月发布。收集了来自 121,000 多名患者的 136,000 多个测序样本,使 AACR Project GENIE数据集成为迄今为止发布的数据量最大的完全公开癌症基因组数据集。
15、hugo-apero-docs - 一款优美的hugo博客主题
贡献者(GitHub ID)¶
「Openbiox 生信周刊」运维小队:
@ShixiangWang@kkjtmac@NiEntropy@He-Kai-fly@JnanZhang@Tomcxf
订阅¶
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。

(完)