生信爱好者周刊(第 58 期):说说你是怎么度过🐑了的日子?¶
这里记录每周值得分享的生信相关内容,周日发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。
封面图¶
本周话题:说说你是怎么度过🐑了的日子?¶
身边越来越多的人变成了小羊人。变🐑后,你是如何熬过这个阶段的?
@kkjtmac - 侥幸感染了“优良”毒株,烧了一晚就退了,后面就是咳嗽流涕,对症支持治疗后最终痊愈。总体感受比普通感冒难受多了,该吃药的时候还得吃,如果不能缓解或者加重还是就近医院就诊治疗吧~
@ShixiangWang - 我们近期很多人都(在)经历变羊的过程,我自己在家里躺了三四天,前两天发烧难受,后面两天咳嗽难受,现在还在咳嗽流鼻涕,整个过程感觉到了大自然对自己的不友好。不管咋样,我们为活着而活着,很多事情不需要找那么多借口,就像我们的抗疫专家们何必去创造各种名词方便编数据,坦然接受,认真对待,好好休息保重身体,以后继续学习和工作以便于能活着。
@匿名 - 第一天,嗓子有些不舒服,到了晚上开始有痰了;第二天,嗜睡,浑身酸痛,在床上躺了一天,越睡头越疼,感觉再睡下去我可能要死在宿舍了,想起师兄前两天说的有个同学在外面租房子住一个人寄了,我现在也是一个人,想到这慌极了;第三天,状态好多了,还有些咳嗽。 总结:一个人生病还是挺危险的,身体再难受,也一定要按时吃饭喝水吃药,不然只会加重病情恶性循环。
生信研究¶
1、NAR | GPSAdb,给你的数据分析加入基因扰动信息
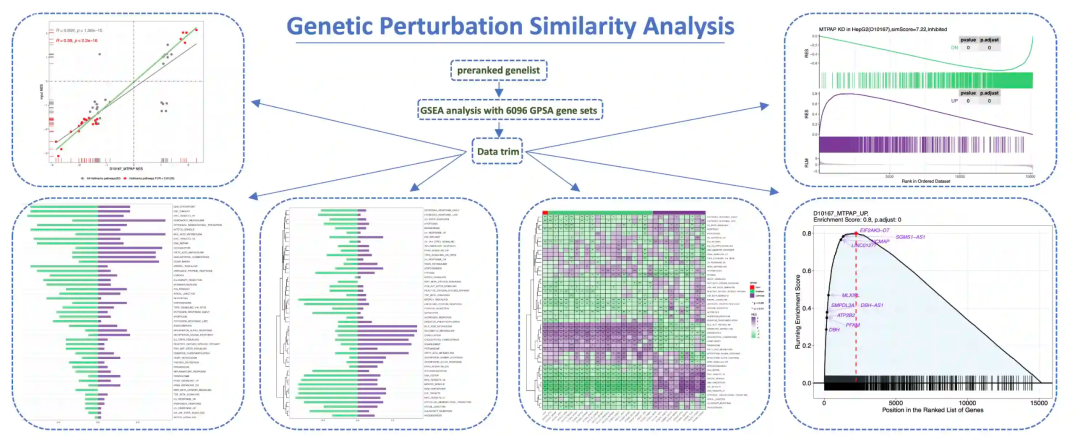
基因敲除方法通常用于探索感兴趣基因的功能,但目前还没有系统收集扰动数据的数据库。本研究开发一个全面的人类扰动数据库(GPSAdb, https://www.gpsadb.com/ )。当前版本的GPSAdb收集了与1458个基因相关的3048个RNA-seq数据集,这些基因被siRNA、shRNA、CRISPR/Cas9或CRISPRi敲除/下调。该数据库提供了对这些数据集的全面探索,并生成了6096个新的扰动基因集(分别向上和向下)。GPSAdb整合了这些基因集,并开发了一个在线工具——遗传微扰相似性分析(GPSA),以从差异基因表达数据中识别潜在的因果微扰。GPSAdb是一个功能强大的平台,旨在帮助生命科学研究人员方便地访问和分析公共扰动数据,并深入探索差异基因表达数据。
- 论文链接:https://academic.oup.com/nar/advance-article/doi/10.1093/nar/gkac1066/6842882#382499840
- 工具地址:http://guotosky.vip:13838/GPSA/, https://www.gpsadb.com
2、Nat Biomed Eng | 基于自监督深度学习的全切片病理图像快速可扩展搜索
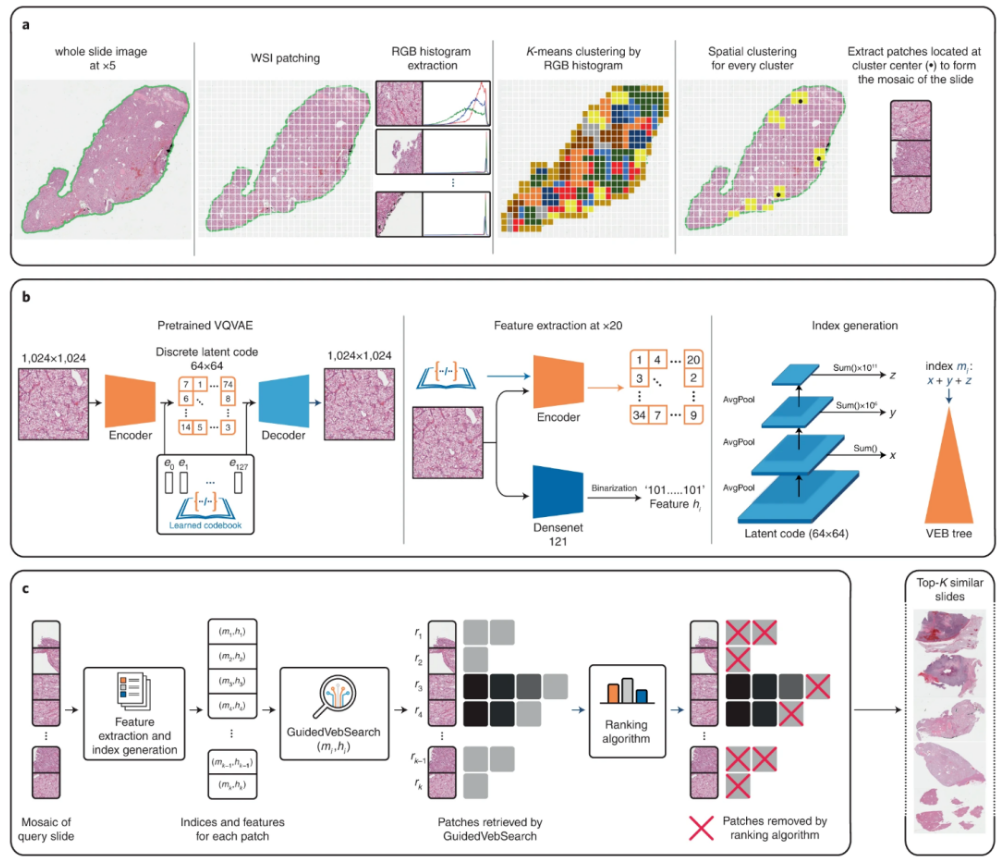
数字病理学的采用使得管理数十亿像素全切片病理图像(WSIs)的大型存储库成为可能。在不需要监督训练的情况下,在大型存储库中计算识别具有相似形态特征的WSIs具有重要的应用价值。然而,搜索相似WSIs的算法的检索速度往往与资源库的大小成正比,这限制了它们的临床和研究潜力。本文展示了可以利用自监督深度学习以独立于存储库大小的速度搜索和检索WSIs。作者将该算法命名为SISH(用于自我监督的组织学图像搜索),并作为一个开源包提供,它只需要用于训练的图像级注释,将WSIs编码为有意义的离散潜在表示,并利用树数据结构进行快速搜索,然后使用基于不确定性的排序算法进行WSI检索。
- 论文链接:https://www.nature.com/articles/s41551-022-00929-8
3、Nat Commun | 基于粪便微生物组的机器学习多类诊断模型
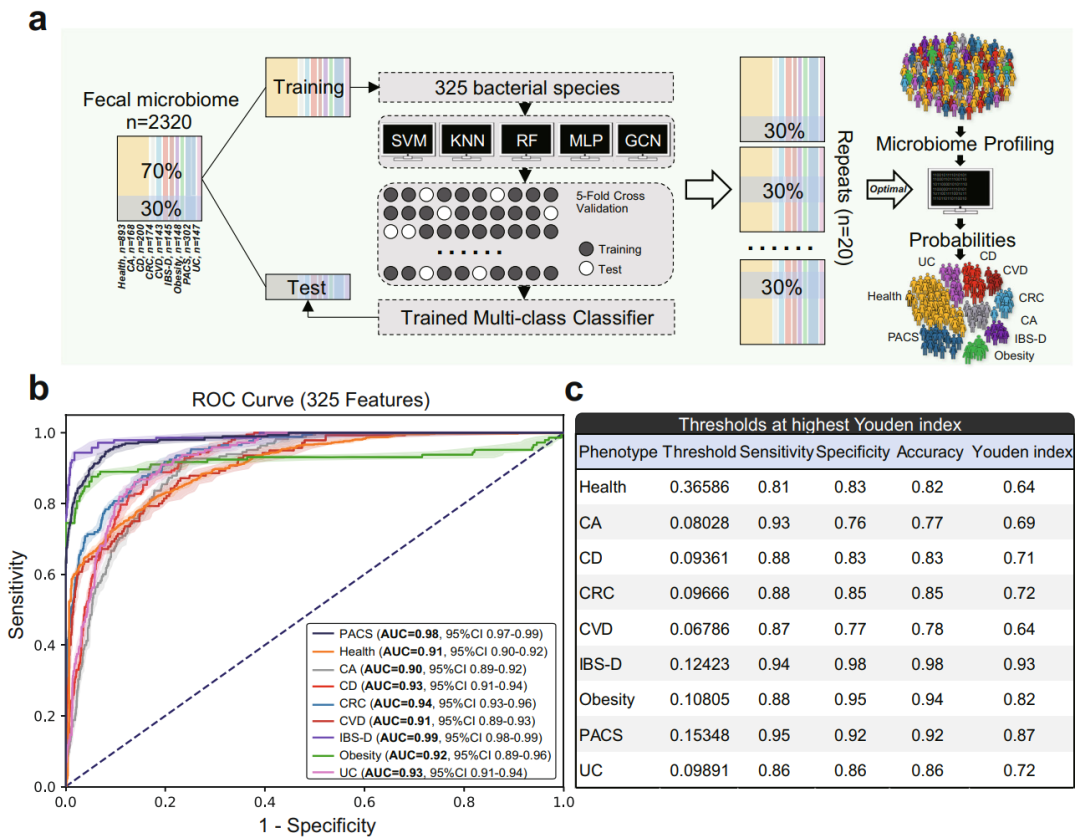
香港中文大学黄秀娟教授团队在Nature Communications上发表的题为“Faecal microbiome-based machine learning for multi-class disease diagnosis”的研究文章。对不同疾病表型的2320名香港华人的粪便样本宏基因组测序,接着通过机器学习算法构建疾病的诊断模型,并通过一系列已发布的公共宏基因组数据集对模型进行验证。文章提供了粪便样本宏基因组测序数据可从ENA下载。
- 论文链接:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9649010/
- 分析代码:https://github.com/qsu123/multi_class_diagnosis
- 测序数据:https://www.ebi.ac.uk/ena/browser/view/PRJNA841786
博文资讯¶
4、clusterProfiler | 单细胞的marker genes做功能富集分析
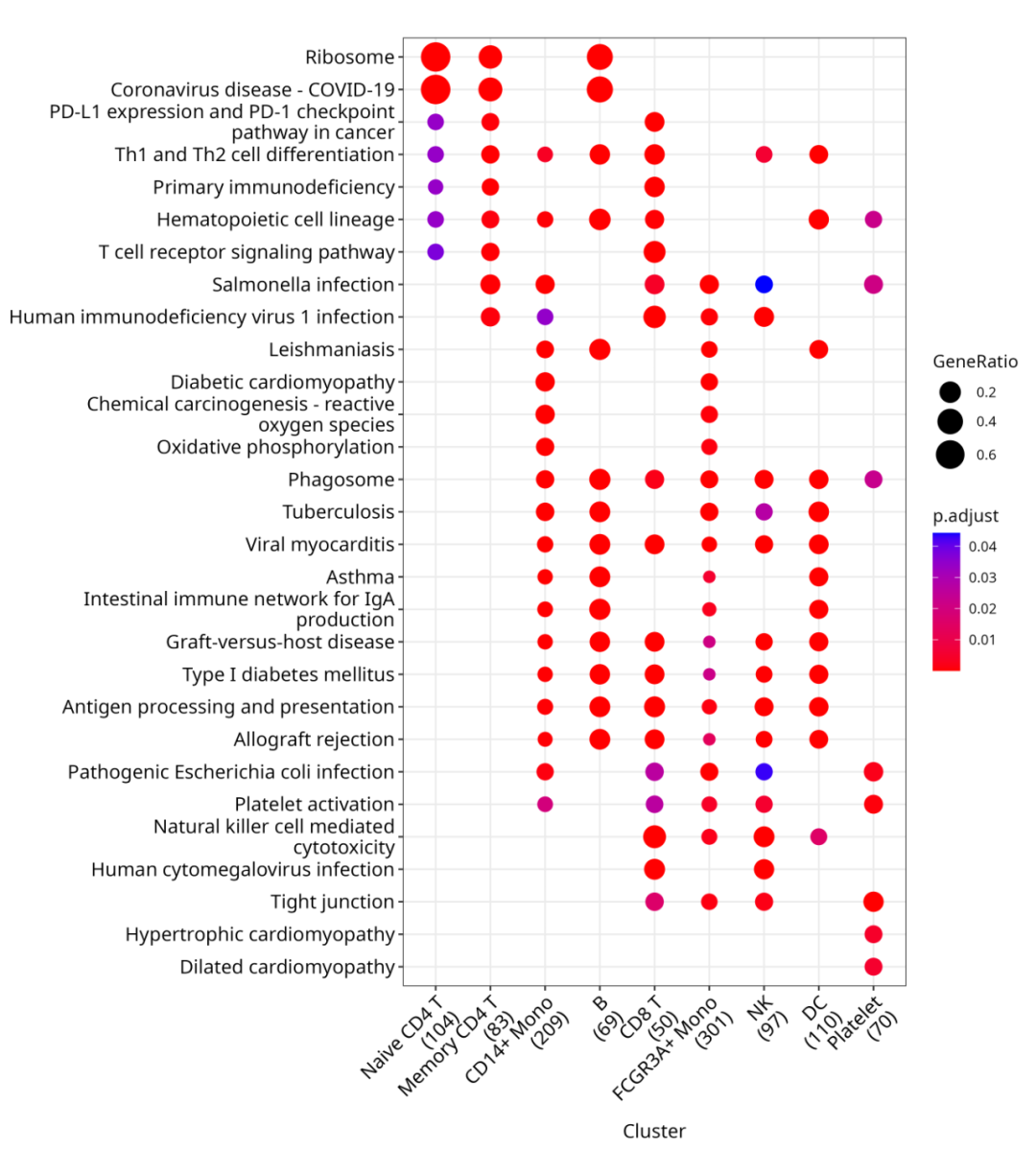
一行代码解决单细胞marker gene的富集分析。
- 工具链接:https://github.com/YuLab-SMU/clusterProfiler
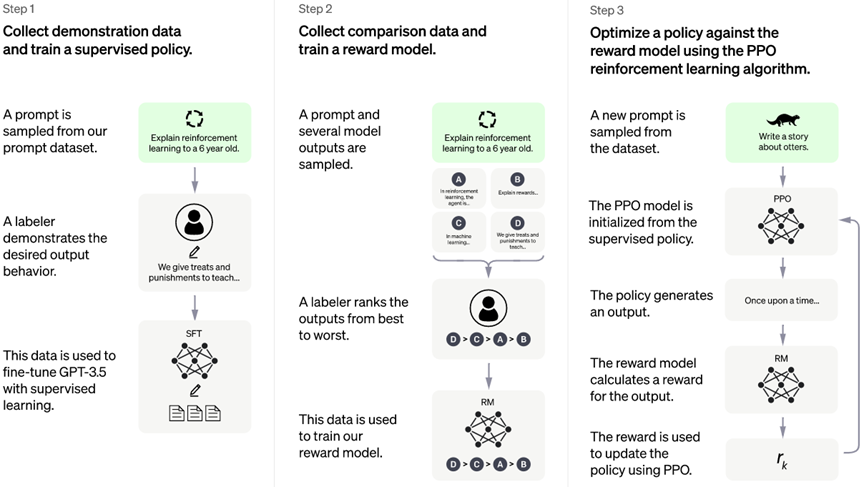
ChatGPT是OpenAI开发的大型预训练语言模型,它通过对话的方式进行交互,ChatGPT可以回答后续问题,承认错误,挑战不正确的前提并拒绝不适当的请求。
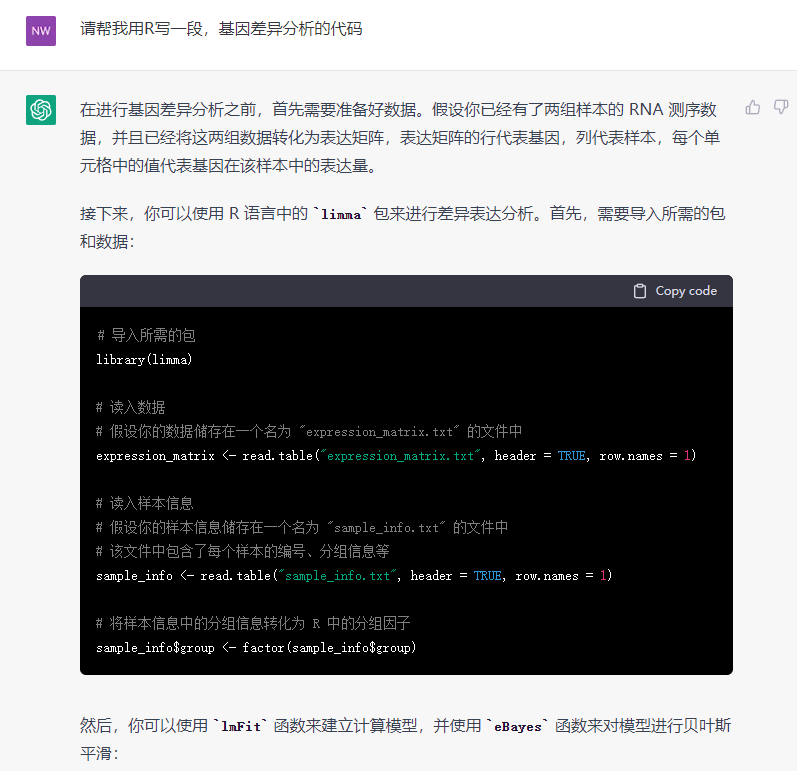
第一次用感觉好神奇,可惜回答有字数限制,提问太频繁会报错。要是有单机版的就太香了!没有国外的手机号注册不了,送大家个账号:账号:nwnz19800123208@163.com 密码:6sa2a06FfW
- 官网链接:https://chat.openai.com/chat
6、熊读文献|Nature Cancer:高度非整倍体的非小细胞肺癌,放疗同步免疫治疗更敏感
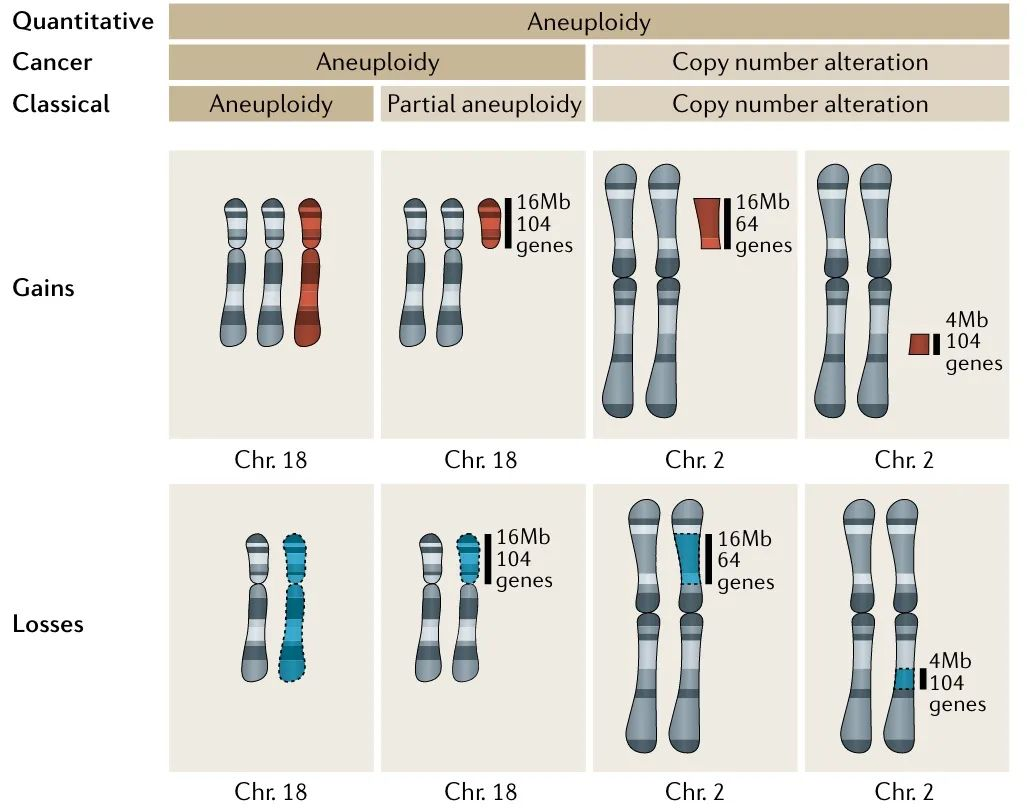
本文熊对非整倍性与近期研究进行了相关的介绍解读。
这里也提到一篇 NG 文章,也有相关的解读。比较奇怪的是,研究者自己都发现了非整倍性与拷贝数负载有极高的相关性,那突出这个非整倍指标的意义我个人还是持保留意见。——@ShixiangWang
工具¶
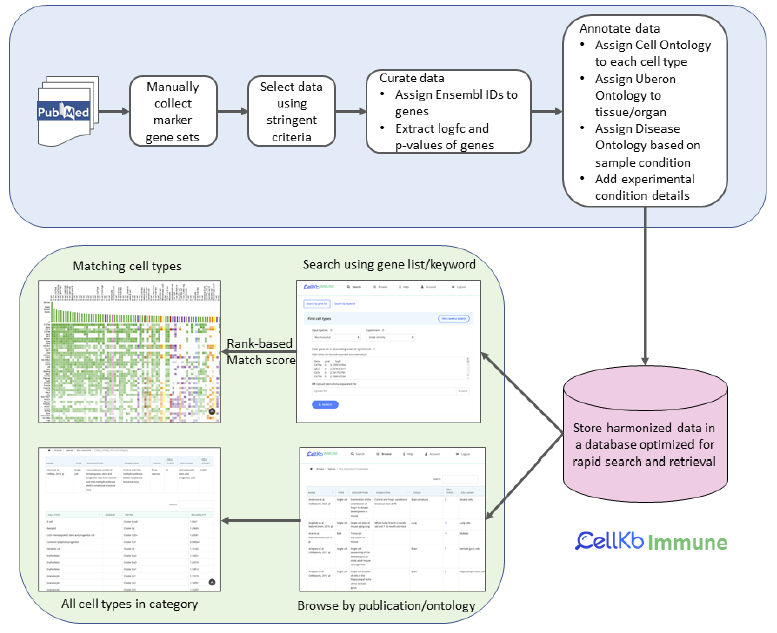
对于基础研究的科研工作者来说,小鼠是进行功能机制研究中最常用的动物模型。因此,在单细胞测序产生的数据中,除了最多的人来源的研究外,紧接着就是小鼠的数据。本文介绍一款专门针对小鼠单细胞数据进行细胞注释的网站:CellKb Immune,不同于很多其它R包或者工具,只能对那些会数据分析的人群,这个网站对所有科研人员都非常友好,只需要点击就能对数据类型进行注释。
8、时序基因共表达网络Time-ordered Gene Coexpression Network (TO-GCN)
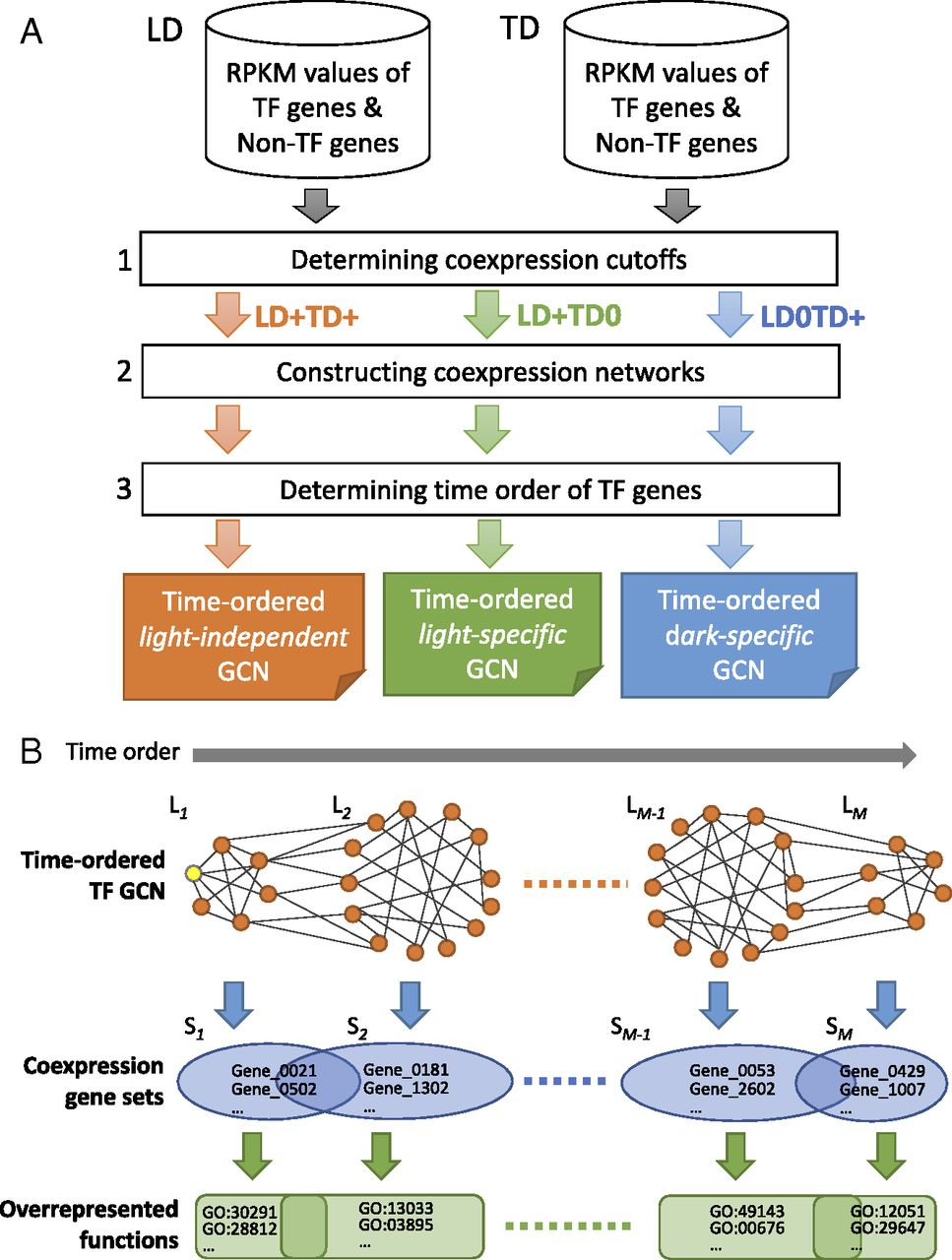
时序基因共表达网络(TO-GCN)是基于三维(基因表达、条件和时间)数据所构建pipeline。 该pipeline包含三个步骤:(1)确定cutoff值(2)为不同的共表达类型构建八个 GCN(3)为感兴趣的 GCN 中的节点确定时间排序级别。
- 工具链接:https://github.com/petitmingchang/TO-GCN
- 论文链接:https://www.pnas.org/doi/abs/10.1073/pnas.1817621116
9、tdiyxl
tidyxl将Excel文件中的非表格形式的数据导入到r中。它以tidy数据结构展示单元格内容、位置、格式和注释,以便进一步操作,特别是由unpivotr包进行操作。它支持基于xml的文件格式’.xlsx ‘和’.xlsm’, 通过嵌入式RapidXML c++库实现xlsm。它不支持二进制 ‘.xlsb’或’ .xls ‘等文件格式。
- 工具链接: https://github.com/nacnudus/tidyxl
10、CRISPRcleanR | 处理 CRISPR-Cas9相关全基因组测序数据的R包
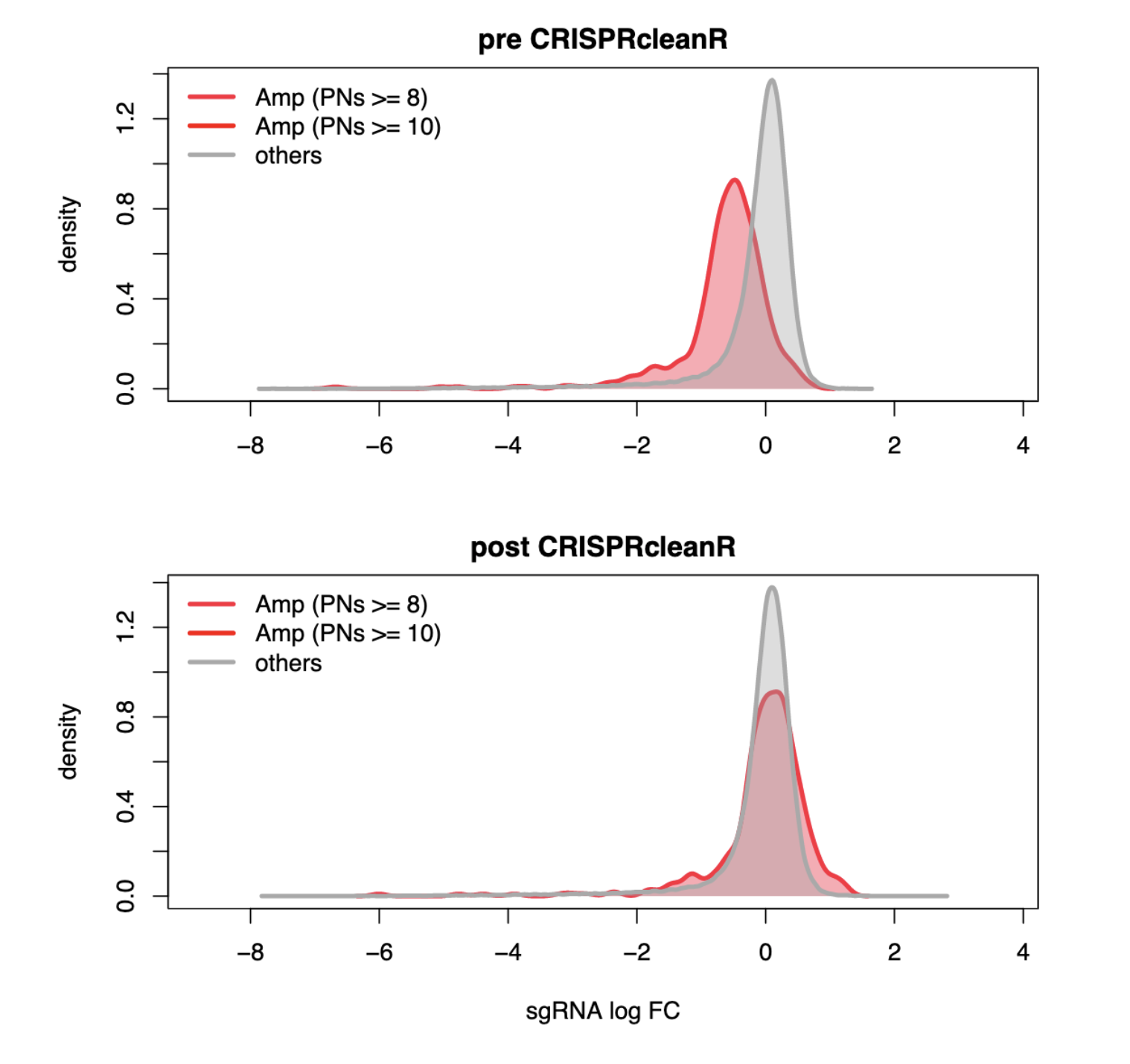
CRISPRcleanR是一个R包,用于处理汇集的全基因组CRISPR-Cas9所衍生的必需性谱。这些必要性谱评估因sgRNA敲除靶向破坏基因而导致的细胞适应性损失或增益的程度。
- 工具链接:https://github.com/francescojm/CRISPRcleanR
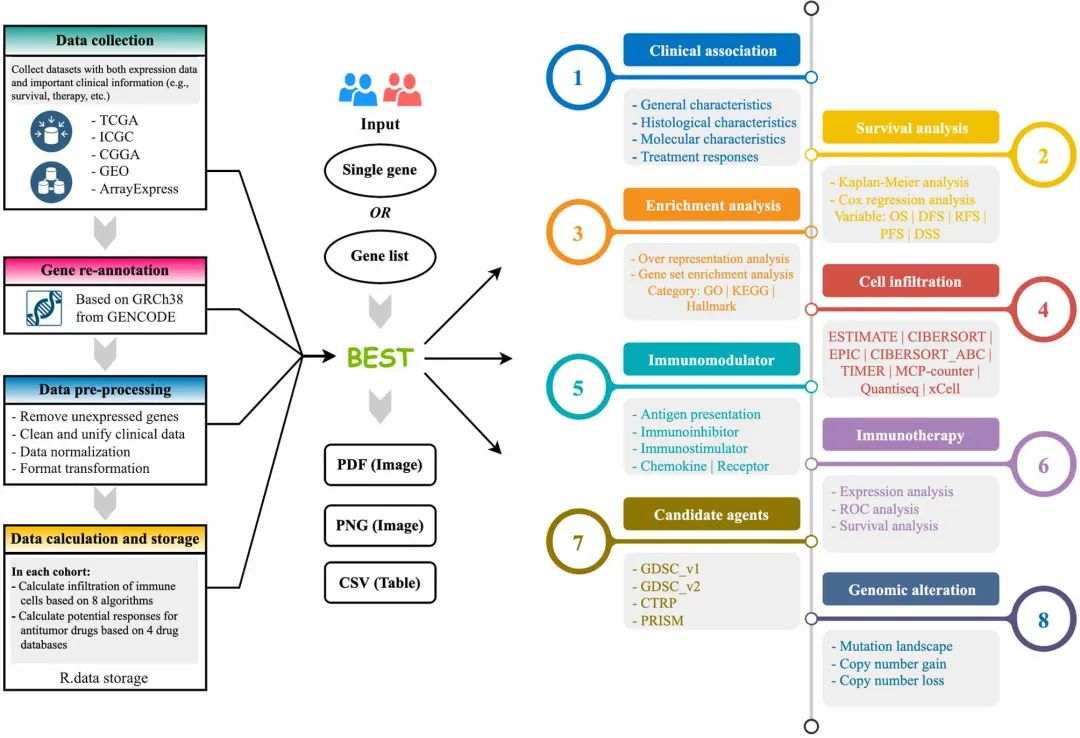
11、BEST:一站式Biomarker多队列多层面分析利器
资源¶
12、生信算法课程 DS202

本课程的目标是提供生物数据分析的算法和数据结构的广泛概述。将重点研究基因组学和相关问题,如生物序列的高通量模式匹配、数据压缩算法、基因挖掘、基因组组装和系统发育。同时提供实践编程作业展示实际测序数据的复杂性。这里列出了暂定的主题和先决条件。在本课程中学习的许多算法技术也适用于生物学以外的领域,如文本挖掘,自然语言处理。
- 资源链接:https://sites.google.com/view/ds202/home
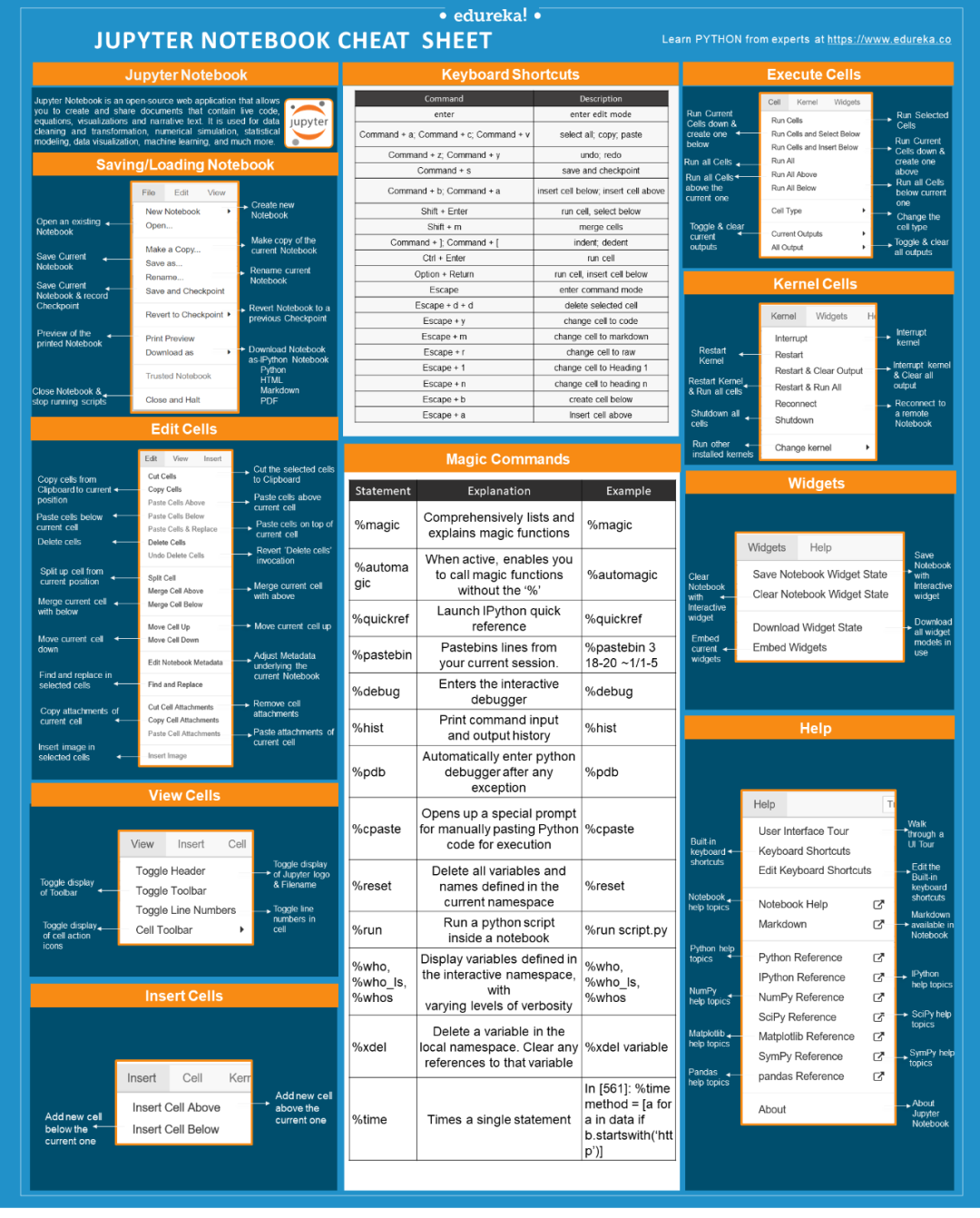
本推文整理了Jupyter Notebook操作界面详细功能介绍及相关快捷键。
- 资源链接:https://mp.weixin.qq.com/s/S8HVSO9oj9dkUkU3mGFeqA
历史上的本周¶
2022年1月:第18期:过去50年最重要的统计学思想是什么?
贡献者(GitHub ID)¶
「Openbiox 生信周刊」运维小队:
@ShixiangWang(王诗翔)@kkjtmac(阚科佳)@NiEntropy(赵启祥)@He-Kai-fly(何凯)@JnanZhang(张佳楠)@Tomcxf(陈啸枫)@wangdepin(王德品)
订阅¶
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。

(完)