生信爱好者周刊(第 54 期):人类和人生的意义¶
这里记录每周值得分享的生信相关内容,周日发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。
封面图¶

本周话题:人类和人生的意义¶
我说,人生是有意义的,而人类则是没有意义的。 人生的意义是什么呢?它的意义就在于为没有意义的人类工作、服务等等,其目的不外乎是使人类生活得更好并得以延续。 反正人类是现实的存在,你又是其中一员,你有义务使它发展延续。你只要这样做了,你的人生就具有了意义,或者说价值,并不一定要去理会人类存在的意义。
@kkjtmac - 还没想透彻,就引用文中有同感的一句话:“保持工作,做一点有益于社会的事情,只有这样才能在没有意义的世界里找到一点意义。”
@ShixiangWang - 小时候觉得人类是一个整体,长大后觉得个人的意义也难确定。随着年岁长大,忙碌替换了想象,疲惫替换了玩闹,人生的意义被越来越多生活的东西填满。这是越来越没有意义,还是有越来越有意义呢?各人各解吧。
生信研究¶
1、Cell | 单细胞空间组学“活字印刷术” Pixel-Seq
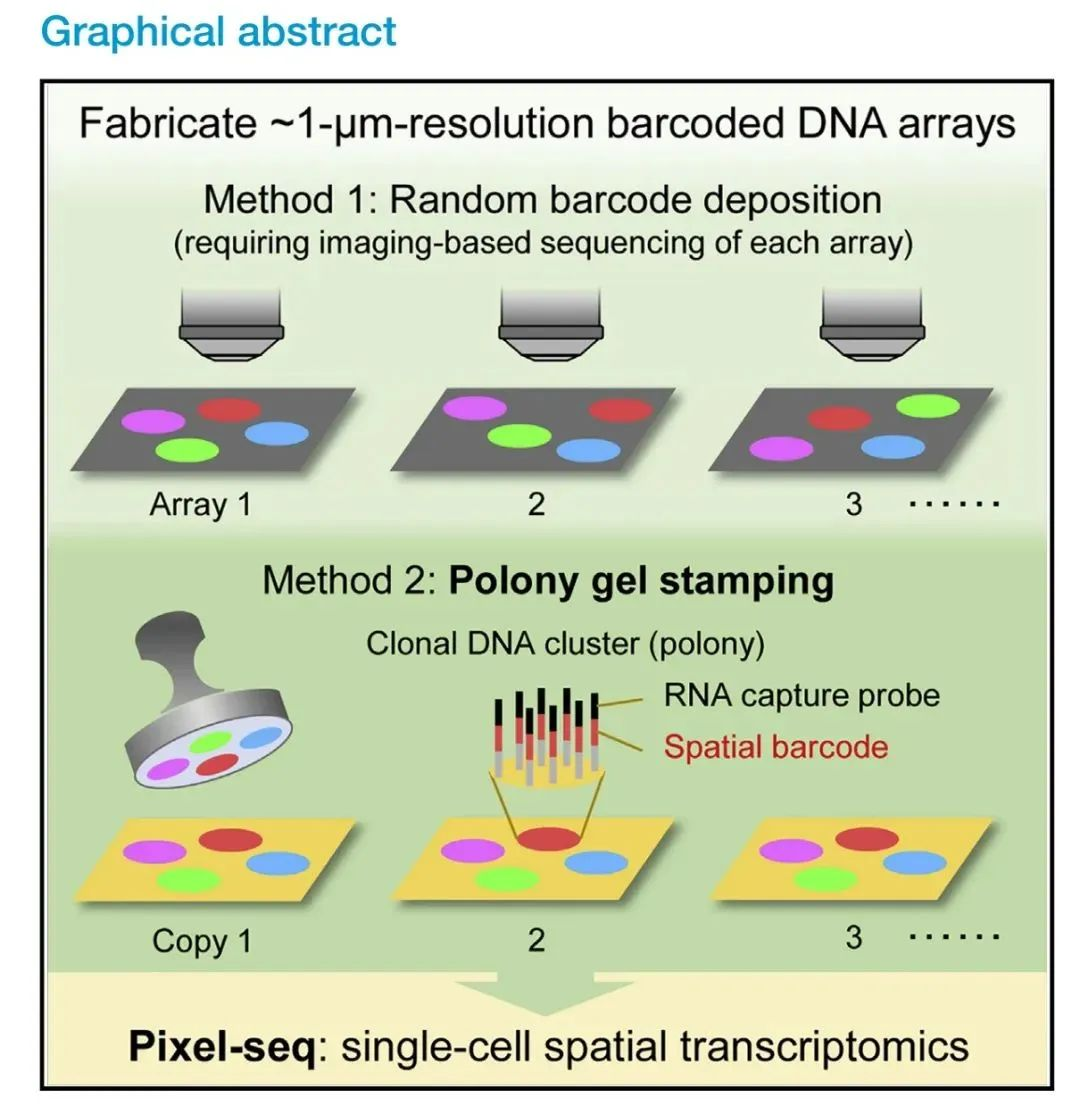
当前各类单细胞空间组学技术以及相应DNA芯片的成本仍然很高,不利于该技术的推广。研究团队计划将polony gel芯片印刷技术运用于芯片的大规模量产,应用到更多领域。他们相信芯片的印刷技术不仅能极大降低芯片的生产成本,还将能大规模应用于当前挑战性比较强的研究领域,比如单细胞、亚细胞空间多组学。该技术不仅将改变生物空间组学,还会推进DNA芯片在其他研究领域中的更广泛应用。
- 论文链接:https://doi.org/10.1016/j.cell.2022.10.021
2、Cancer Cell | 癌细胞“躺赢”:表观遗传被破坏,不响应应激带来的选择优势
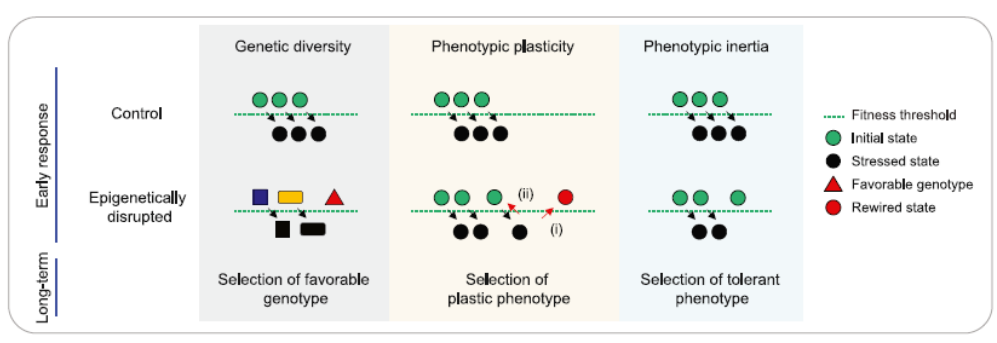
表观遗传调控基因是多种癌症类型中突变最多的,但它们的功能尚不清楚。来自英国弗朗西斯克里克研究所的Paola Scaffidi团队模拟了病人中广泛存在的表观遗传相关突变,发现表现调控网络的破坏并不促进亚克隆基因型的选择,而是通过全局转录组调控来阻止细胞相应应激,从而增加癌细胞对于不适宜环境的耐受度,踧踖抵抗压力亚群的出现。该成果近期已发表于Cancer Cell上。
- 论文链接:https://www.sciencedirect.com/science/article/pii/S1535610822004937
3、Cell | 全基因组Perturb-seq助力表型发现
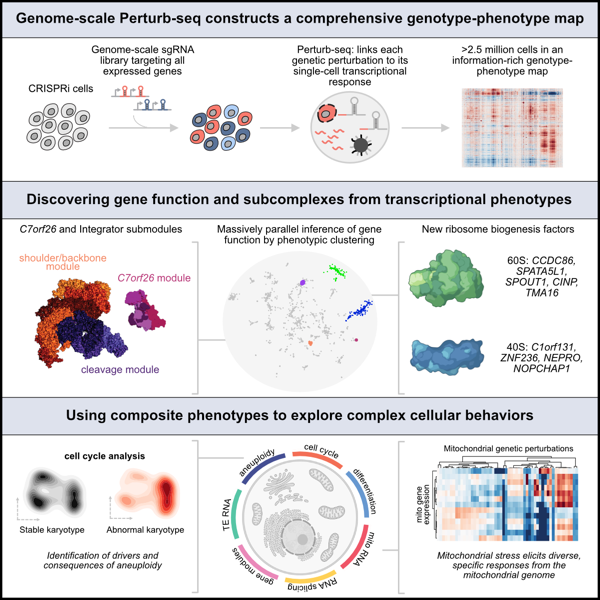
第一个在人类细胞全基因组Perturb-seq,利用CRISPR-Cas9基因组编辑技术同时对几百万个细胞进行随机不同基因的敲除,然后利用单细胞测序技术识别细胞的敲除基因,同时记录细胞转录组水平的变化,从而实现全基因组水平的基因敲除并测序。可以想象随着这个技术的不断成熟,未来通过挖掘Perturb-seq数据,寻找基因敲除后对应的表型通路,为尚未开发的潜在治疗靶点的研究开发提供新的依据。
- 论文链接:https://pubmed.ncbi.nlm.nih.gov/35688146/
- 测序数据:https://gwps.wi.mit.edu/
- 论文代码:https://github.com/thomasmaxwellnorman/Perturbseq_GI;https://github.com/josephreplogle/guide_calling
博文资讯¶
4、projectLSI - 将你的单细胞或bulk转录组数据映射到参考数据集中
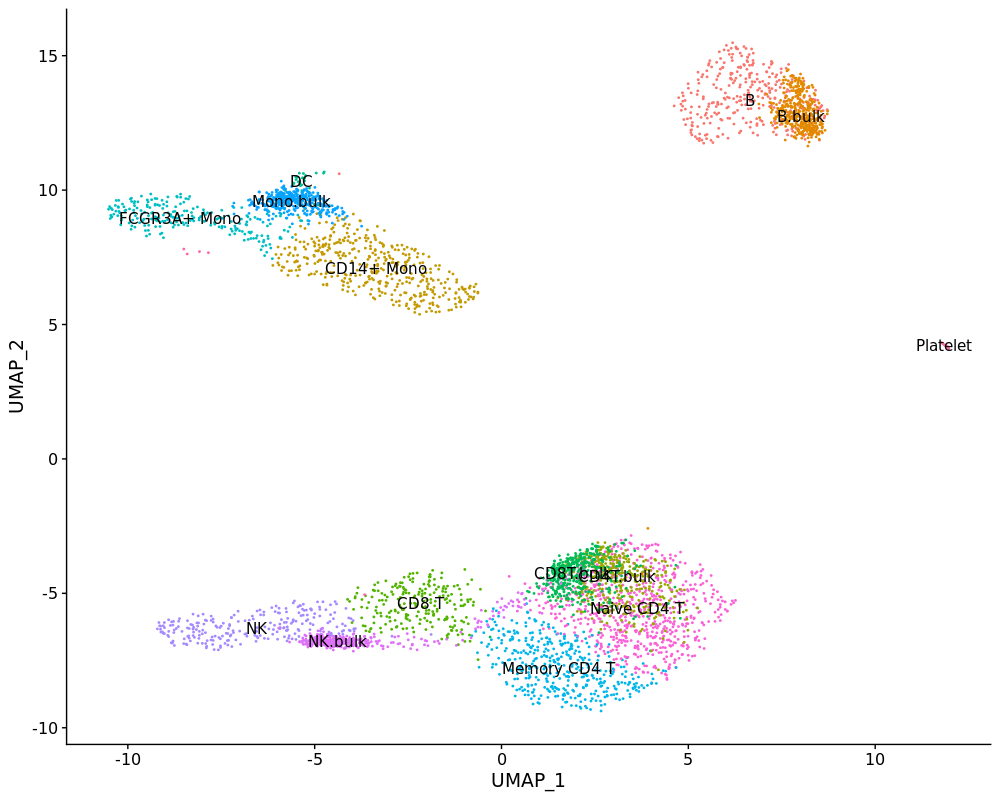
本文介绍 projectLSI 包的使用。在单细胞数据分析过程中,我们经常会遇到不同样本之间整合的批次效应和细胞类型注释的困难,projectLSI包利用term frequency–inverse document frequency (TF-IDF) transformation and latent semantic indexing (LSI)算法进行数据降维转换,可以将query的单细胞或bulk转录组数据集映射到reference参考数据集中以消除潜在的批次效应,同时也可以利用bulk转录组数据验证单细胞注释分群的结果。
5、PyClone-VI 的使用方法–肿瘤基因组测序数据分析专栏
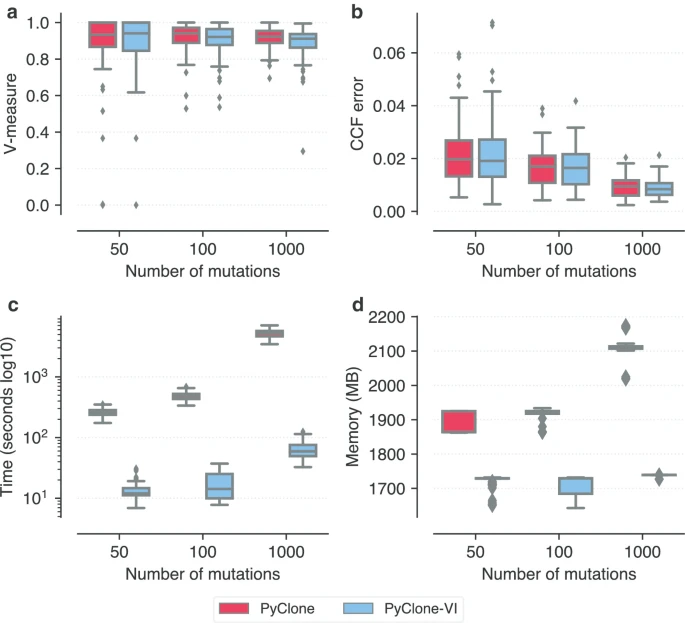
本文首先解读了PyClone-VI性能评估的文章,再介绍了其安装方法和具体使用方法和参数。Pyclone-VI作为Pyclone的升级版本,由同一个团队开发的,运行速度更快,占用内存空间更小,且运行得到的结果和 PyClone 高度一致。
- 论文链接:https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-020-03919-2
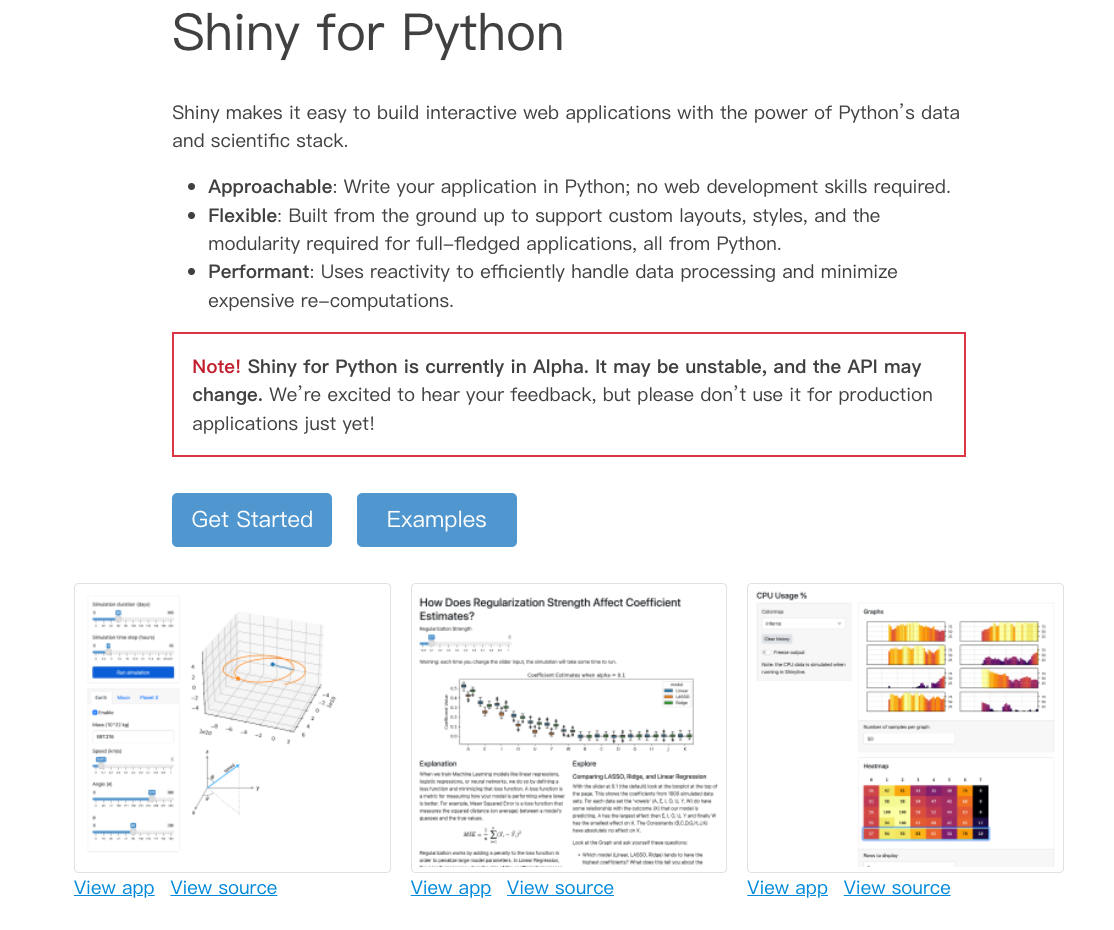
Shiny工具可以轻松的利用Python数据和科学堆栈构建交互式的web应用程序。具有以下特点:
-
Approachable:用Python编写应用程序;不需要web开发技能。
-
Flexible:从头开始构建,以支持成熟应用程序所需的自定义布局、样式和模块化,所有这些都来自Python。
-
Performant:使用反应性来有效地处理数据处理并将昂贵的重新计算降至最低。
工具¶
DrugBank数据库是阿尔伯塔大学提供的一个生物信息学和化学信息学数据库,是一种独特的生物信息学和化学信息学资源,它将详细的药物数据和全面的药物目标信息结合起来。最近发布的DrugBank包含超过50条和药物相关条目,其中包括2723种经批准的小分子药物、1540种经批准的生物技术(蛋白质/肽)药物、131种营养品和6451种实验药物。此外,5236个非冗余蛋白(即药物靶标/酶/转运体/载体)序列与这些药物条目相关联。每个DrugCard条目包含200多个数据字段,其中一半用于药物/化学数据,另一半用于药物靶标或蛋白质数据。
- 工具链接: https://go.drugbank.com/
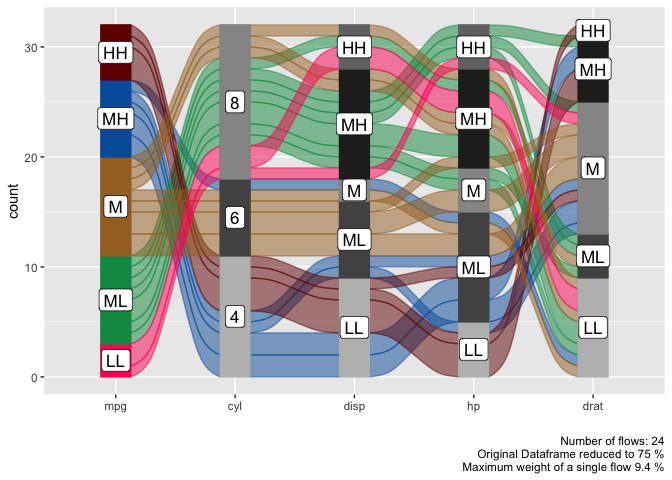
easyalluvial是快速绘制冲积图(Alluvial diagram)的R包,其外观类似桑吉图,从多个维度展示分类数据流。
9、showyourwork - LaTeX中完全可复制的、开源的科学文章

showyourwork 是一个用于开源科学文章的工作流管理工具。如果你想让你的研究文章可复制、可扩展、透明,或者只是非常棒,你已经找到了正确的工具。showyourwork 自动化你的整个工作流程,将其包装成一个独立的食谱,任何人都可以遵循,并在点击一个按钮,使用复制你的结果。
这里有个快速开始教程:https://showyourwork.readthedocs.io/en/latest/quickstart ,使用Latex或者喜欢开放科学的读者不妨试试。
10、parallel-fastq-dump - 多线程运行处理SRA文件
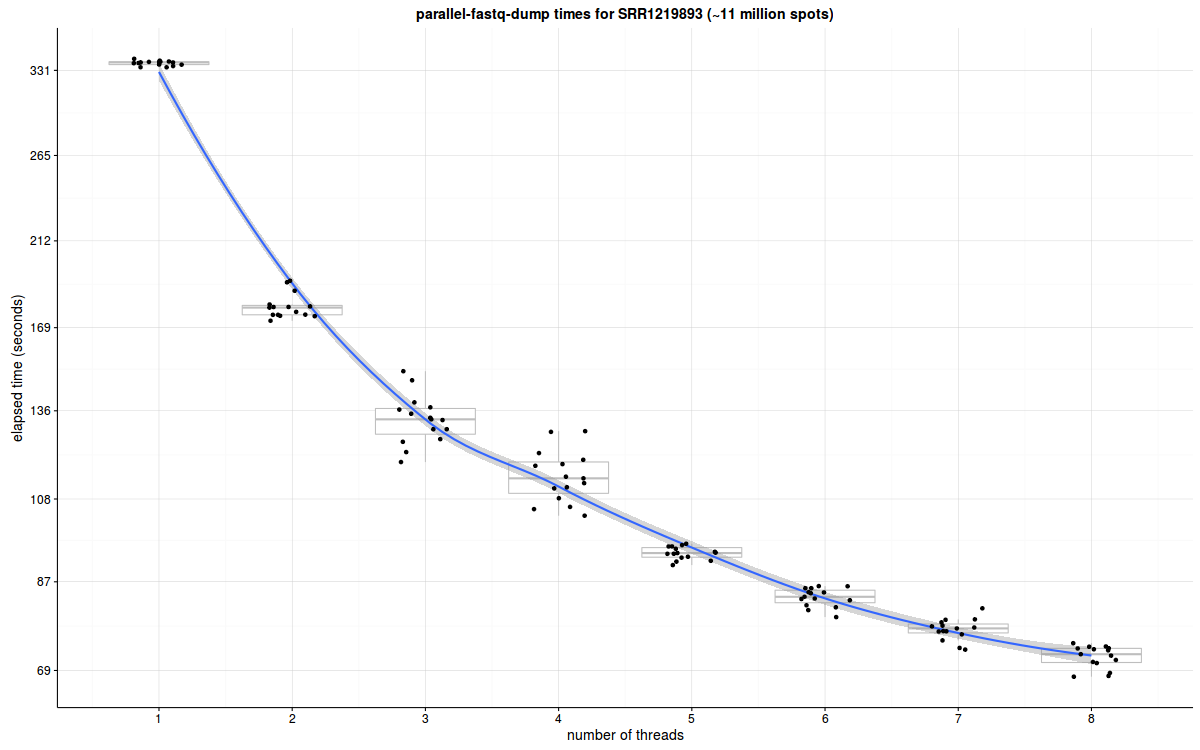
parallel-fastq-dump是能多线程运行fastq-dump处理SRA文件的工具,而且与另一个常用的多线程工具fasterq-dump相比,还有–gzip选项可以直接生成压缩格式文件。经测试,调用12线程,parallel-fastq-dump处理SRA文件比fasterq-dump+pigz快2-3倍, 比fastq-dump快8-10倍!
- 工具链接:https://github.com/rvalieris/parallel-fastq-dump
资源¶
11、H12SSL-I | 高性能桌面级服务器的DIY组装教程
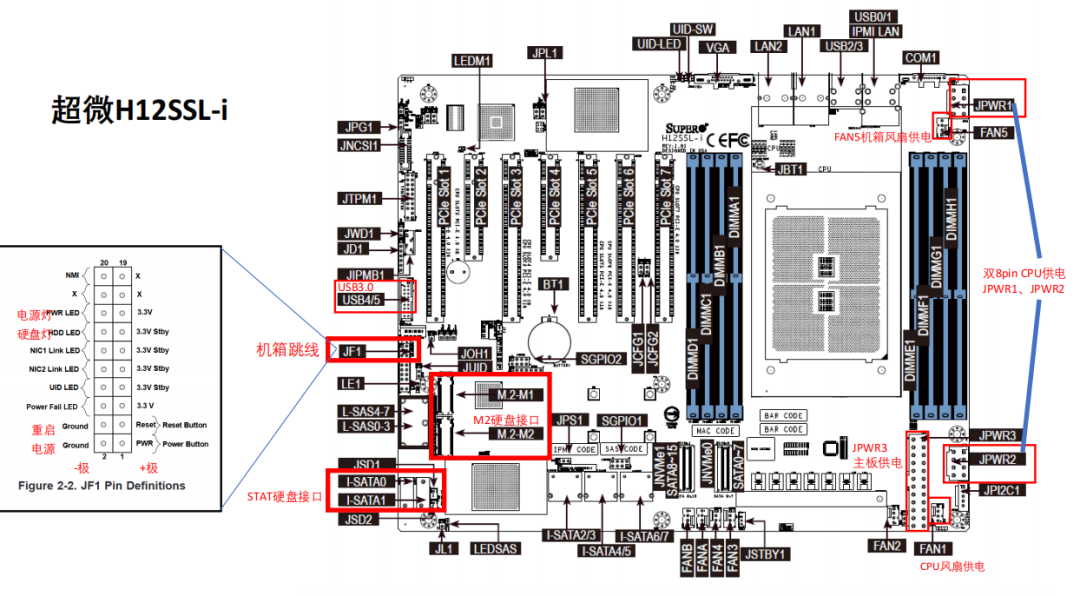
高性能、高拓展性的桌面级服务器组装教程。可以装进ATX小机箱,8个内存插槽最高可支持2T的运行内存,CPU支持目前AMD最顶级的EPYC7003系列服务器处理器以及上一代的7002系列处理器;7个PCle插槽,可以插显卡、网卡、拓展卡等等拓展性非常强(实测不光可以跑生信数据,插上八年前的显卡GTX970 吃鸡、元神无压力,嘎嘎乱杀)。最后提醒一下想入坑的小伙伴,选购配件一定不要贪便宜一定要买有售后的!
13、hrbrthemes - ggplot2主题和字体的拓展资源
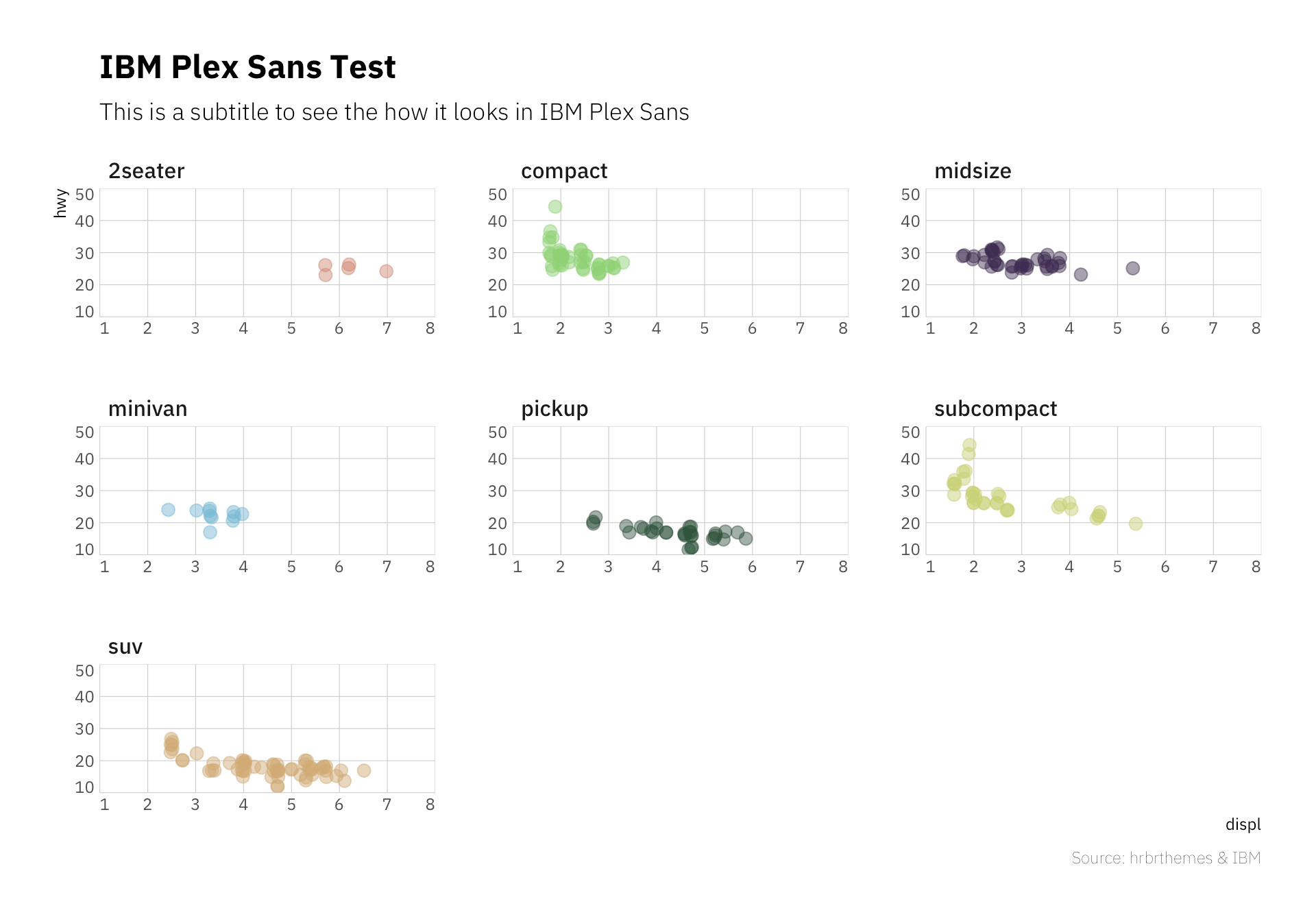
hrbrthemes是一个ggplot2主题的扩展R包,本文展示了该包中的一些特色主题及字体。
历史上的本周¶
贡献者(GitHub ID)¶
「Openbiox 生信周刊」运维小队:
@ShixiangWang(王诗翔)@kkjtmac(阚科佳)@NiEntropy(赵启祥)@He-Kai-fly(何凯)@JnanZhang(张佳楠)@Tomcxf(陈啸枫)@wangdepin(王德品)
订阅¶
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。

(完)