生信爱好者周刊(第166期): 为什么中外科研课题如此不同¶
这里记录每周值得分享的生信相关内容,周日发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。
封面图¶

本周话题: 为什么中外科研课题如此不同¶
文章探讨了中外科研课题选择的差异,以脑研究为例,指出国外多选择果蝇等简单生物进行基础研究,而国内则倾向于选择猴等复杂生物。文章质疑这种差异是否源于中国科研界对企业的过度依赖,以及对基础研究积累和技术磨练的忽视。同时,指出国外科研遵循从简单到复杂的逻辑,先在低等生物上积累经验、改进技术,再逐步向高等生物拓展,而国内部分科研项目可能缺乏这种循序渐进的规划,甚至存在企业主导科研、套取国家经费的现象。 文章揭示了中外科研在选题和组织方式上的差异,强调了基础研究重要性。中国科研应注重循序渐进积累,避免盲目追求复杂课题,同时警惕企业过度介入科研可能带来的问题,确保科研回归科学本质。
生信研究¶
1.Cell Genomics | 新一代基因组浏览器用以整合单细胞和空间多模态数据可视化

西南大学王翊课题组在《Cell Genomics》期刊发布新一代基因组浏览器SGS,用于整合单细胞和空间多模态数据的可视化。该工具用户友好,支持多操作系统,无需编程即可安装使用;具备强大的多用户协同功能,方便团队实时协作和数据共享;支持多种单细胞和空间组学数据的可视化,提供丰富的交互功能和数据比较模式;此外,SGS兼容多种数据格式,与主流分析工具无缝对接,为生命科学研究提供了高效便捷的新工具。
- SGS官网:https://sgs.bioinfotoolkits.net/home
2.Cancer Cell | TCR测序解码鼻咽癌免疫监视密码,突破早期诊断瓶颈
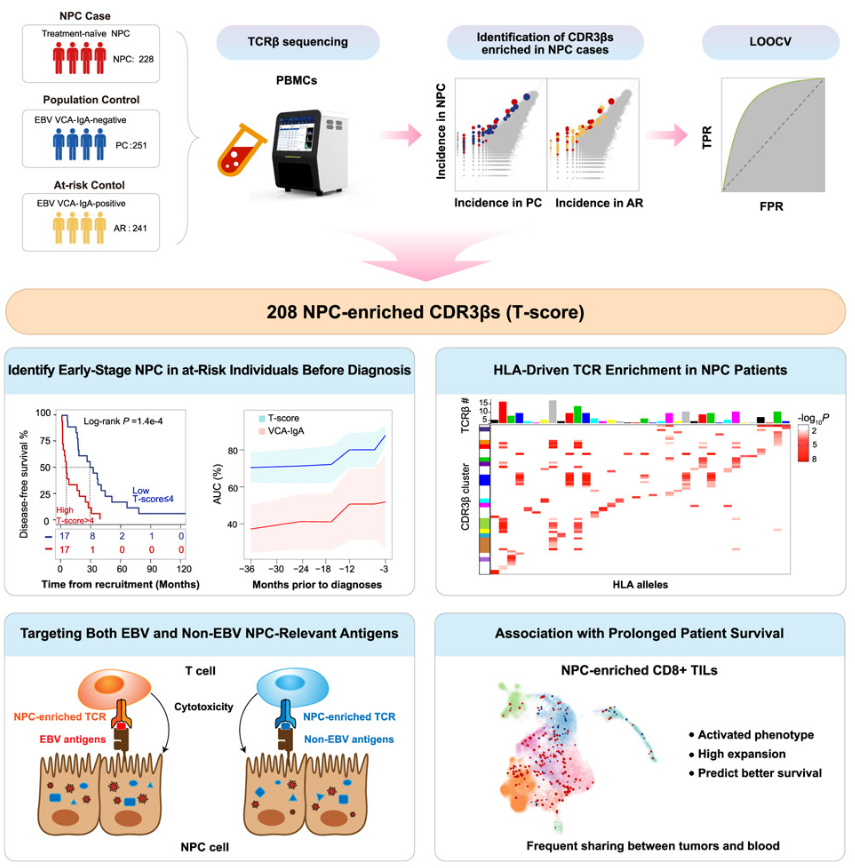
研究首次通过大规模T细胞受体(TCR)免疫组库测序,锁定鼻咽癌特异性T细胞克隆,构建可提前6-12个月预警鼻咽癌发生的T-score模型,并揭示EB病毒(EBV)与肿瘤抗原双重识别的免疫监视机制,为鼻咽癌早诊与细胞治疗提供全新策略。
- 文章链接:https://www.cell.com/cancer-cell/fulltext/S1535-6108(25)00168-0
3.Cell Systems | 基于邻近标记的空间可视化蛋白质组学新技术
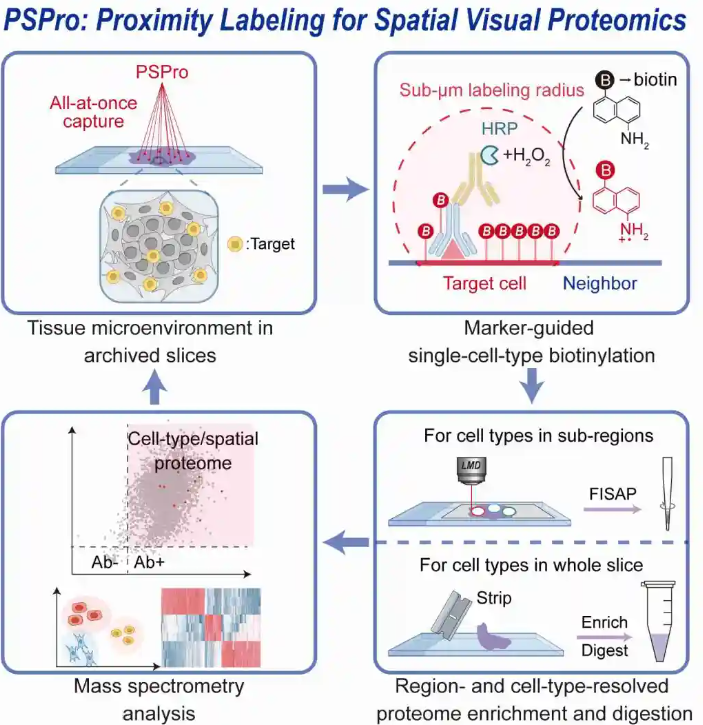
研究基于邻近标记策略开发了一种具有细胞类型分辨率的空间可视化蛋白质组学方法PSPro,该方法可以在亚微米尺度的空间分辨率下一次性标记和富集组织切片中目标细胞类型的蛋白质组,流程简单方便,具有大规模应用潜力。
- 论文链接:https://doi.org/10.1016/j.cels.2025.101291
博文资讯¶
4.使用Cherry Studio + MCP实现自动搜索及下载arxiv文献
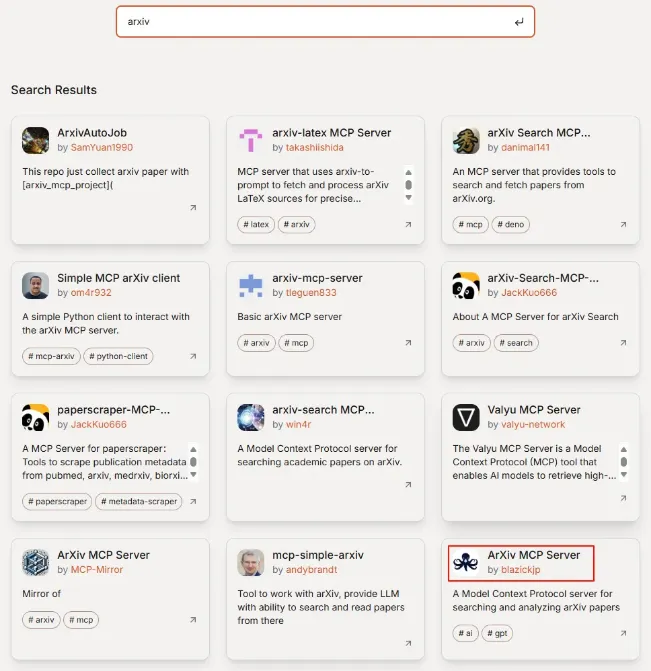
一篇关于利用Cherry Studio及MCP实现自动搜索arxiv文献的教程。下载速度和网络有关系,普通网络下载arxiv可能会比较慢。下载完毕后会自动将PDF论文转换成markdown形式方便AI阅读。如果需要PDF原文,我们也可以在提示词中直接让MCP保留PDF原文。
5.Nature综述 | Transformers与基因组语言模型
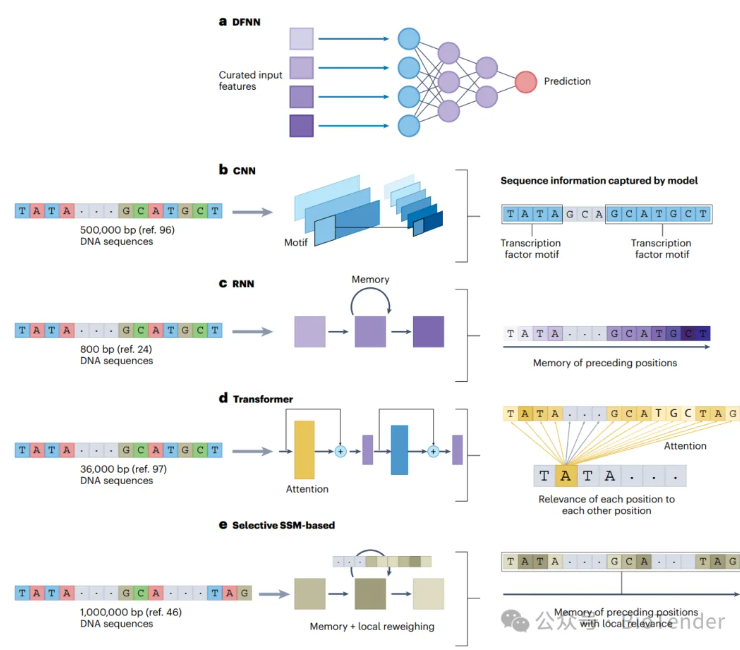
综述将目光投向基因组数据,尝试用Transformer这一AI领域最强大的模型,去挖掘DNA序列中的隐含信息,帮助科学家更高效地预测基因调控、理解突变影响、甚至解析未知的生物机制。 - 文章链接:https://www.nature.com/articles/s42256-025-01007-9
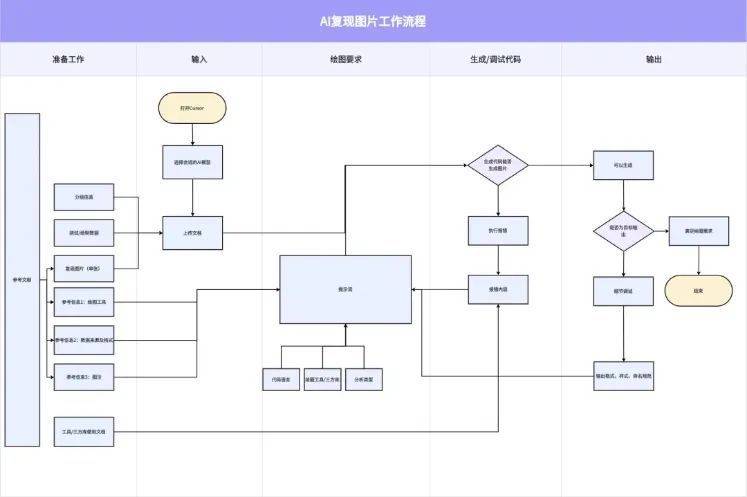
在论文发表、项目申报等场景中,生信人员经常需要生成各种可视化图表来辅助分析和展示研究结果。而想要发好文章,我们通常会参考别人发表的高分论文,希望能复现其中的图片效果。笔者为了帮助生信人员解决这一问题,将前期探索的工作逻辑梳理成一个框架。按照这个框架操作,可以基于AI模型实现图片复现。
工具¶
7.FeedMe

FeedMe 是一款由 Seanium 开发的 AI 驱动的 RSS 阅读器,旨在通过人工智能技术重新定义 RSS 阅读体验。它支持多源 RSS 聚合、AI 摘要生成、定时更新机制、分类浏览、明暗主题切换等功能,并且可以轻松部署到 GitHub Pages 或通过 Docker 在本地服务器上运行。该工具适合希望一站式了解多个信息源动态,但又不想使用传统 RSS 阅读器的用户,提供了轻量级、自由配置和开源的解决方案。
8.RedNote-MCP|超好用的小红书内容访问MCP服务

RedNote-MCP 是一款专门用于访问和分析小红书内容的工具,基于 MCP(Model Context Protocol)协议开发。它可以帮助内容创作者和企业用户更高效地获取小红书上的笔记和评论内容,支持 Cookie 持久化、关键词搜索笔记、命令行初始化等功能,方便开发人员快速集成和使用。
- 相关链接:https://github.com/iFurySt/RedNote-MCP
9.mLLMCelltype | 基于大语言模型的单细胞RNA-seq数据自动注释工具

mLLMCelltype是一个创新的R包和Python包,能够利用大型语言模型(如Claude 3.7、Gemini 2.5等)自动注释单细胞RNA-seq数据中的细胞类型。该工具通过多LLM共识机制提高注释准确性,支持多种LLM模型,可以处理各种组织和物种的单细胞数据。相比传统方法,mLLMCelltype无需预训练数据集,适用性更广,特别适合分析罕见细胞类型或新型数据集。使用者只需提供表达矩阵和标记基因,即可获得准确的细胞类型注释结果。
资源¶
GeeksforGeeks 是一个专注于计算机科学和编程知识的在线学习平台,提供广泛的编程教程、算法、数据结构、编程语言(如 Python、Java、C++ 等)的讲解,以及面试准备、在线课程和实践练习等功能。它旨在帮助程序员和计算机科学爱好者提升技能、准备面试和学习新技术。
11.首个中国开源三万人多组学样本库:西湖生物样本库数据批量下载详细步骤
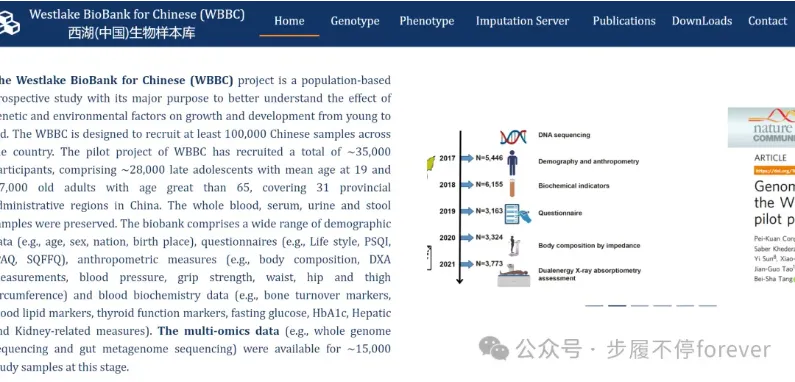 西湖生物样本库(Westlake BioBank for Chinese, WBBC)是一个以人口为基础的前瞻性研究项目,其主要目的是更好地理解遗传和环境因素对从青少年到老年人生长发育的影响。WBBC计划招募至少10万个中国样本。目前,WBBC试点项目已招募约35,000名参与者,包括约28,000名平均年龄为19岁的青少年和约7,000名65岁以上的老年人,覆盖中国31个省级行政区域。研究人员若需要访问原始遗传数据,必须获得中华人民共和国科学技术部和西湖大学机构审查委员会的许可。且研究必须符合中国人类遗传资源管理(HGRAC)的规定。
西湖生物样本库(Westlake BioBank for Chinese, WBBC)是一个以人口为基础的前瞻性研究项目,其主要目的是更好地理解遗传和环境因素对从青少年到老年人生长发育的影响。WBBC计划招募至少10万个中国样本。目前,WBBC试点项目已招募约35,000名参与者,包括约28,000名平均年龄为19岁的青少年和约7,000名65岁以上的老年人,覆盖中国31个省级行政区域。研究人员若需要访问原始遗传数据,必须获得中华人民共和国科学技术部和西湖大学机构审查委员会的许可。且研究必须符合中国人类遗传资源管理(HGRAC)的规定。
这篇文章推荐了人工智能时代单细胞领域必读的10个细胞基础大模型,并提供了模型链接。文章指出,这些AI基础模型是生物医学与AI交叉的范例,通过大规模参数和深度学习架构,能够实现对细胞行为的深度解析,推动生命科学从“试错实验”向“数据驱动”范式转变。文章还提出了开放性讨论问题,包括AI模型的下游任务、效果对比传统算法工具的优势,以及AI模型可以实现而经典软件无法达到的分析场景。
贡献者(GitHub ID)¶
「Openbiox 生信周刊」运维小队:
- @ShixiangWang(王诗翔)
- @kkjtmac(阚科佳)
- @NiEntropy(赵启祥)
- @He-Kai-fly(何凯)
- @JnanZhang(张佳楠)
- @kkjtmac(阚科佳)
- @Tomcxf(陈啸枫)
- @wangdepin(王德品)
- @kongjianyang(空间阳)
- @donghongyu2020(董弘禹)
- @DrRobinLuo(罗鹏)
- @Wangcy-rachel - 王春阳
- @zoe3251 - 舒晨阳
订阅¶
这个周刊每周日发布,同步更新在微信公众号「优雅R」(elegant-r)上。
微信搜索“优雅R”或者扫描二维码,即可订阅。
